Типы ошибок в программном обеспечении
Существуют три
типа ошибок программирования:
–
синтаксические
ошибки,
–
ошибки
выполнения,
–
семантические
ошибки.
В
любом языке программирования каждое
предложение (оператор) строится по
определенным правилам. Когда
в программе встречается предложение,
которое нарушает эти правила, то говорят
о наличии синтаксической ошибки.
Синтаксическая ошибка легко обнаруживается
компиляторами и интерпретаторами
языка и легко исправляется.
Второй
тип ошибок
обычно возникает во время выполнения
программы (их принято называть
исключительными ситуациями). Такие
ошибки имеют другую причину. Если в
программе возникает исключение, то это
означает, что случилось непредвиденное:
например, программе передали
некорректное значение или программа
попыталась разделить какое-то значение
на ноль, что недопустимо с точки зрения
математики. Если операционная система
присылает запрос на немедленное
завершение программы, то также
возникает исключение. Ошибки выполнения
легко обнаруживаются, однако устранение
их причин может оказаться нетривиальной
задачей.
Семантические
(смысловые) ошибки
– это
применение операторов, которые не
дают нужного эффекта (например, (a–b)
вместо (a+b)),
ошибка в структуре алгоритма, в логической
взаимосвязи его частей, в применении
алгоритма к тем данным, к которым он
неприменим и т.д. Правила семантики
не формализуемы. Поэтому поиск и
устранение семантической ошибки и
составляет основу отладки.
3.1.2. Причины появления ошибок в программном обеспечении
Прежде всего
необходимо понять первопричины ошибок
программного обеспечения и связать
их с процессом создания программных
комплексов. В данном учебном пособии
считается, что создание программного
обеспечения можно описать как ряд
процессов перевода, начинающихся с
постановки задачи и заканчивающихся
большим набором подробных инструкций,
управляющих ЭВМ при решении этой задачи.
Создание программного обеспечения
в этом случае – просто совокупность
процессов трансляции, т.е. перевода
исходной задачи в различные промежуточные
решения, пока наконец не будет получен
подробный набор машинных команд [1].
Когда не удается полно и точно перевести
некоторое представление задачи или
решения в другое, более детальное, тогда
и возникают ошибки в программном
обеспечении.
Для того чтобы
подробнее исследовать проблему ошибок
в программном обеспечении (ПО),
рассмотрим различные типы процессов
перевода при его создании.
Создание ПО
начинается с формирования требований
пользователя, т.е. с разработки описания
решаемой задачи. Такое описание имеет
вид перечня требований пользователя.
В некоторых случаях пользователь
составляет этот перечень сам. В других
случаях это делает разработчик ПО в
беседе с пользователем, либо исследуя
его потребности, либо самостоятельно
оценивая эти потребности в будущем,
либо комбинируя перечисленные методы.
В данном учебном пособии будем считать,
что на данном этапе ошибки не вносятся.
1. Первый процесс
– перевод требований пользователя в
цели программы. Хотя на этом шаге
объем перевода невелик, здесь требуется
явно выделить и оценить довольно много
компромиссных решений, которые будут
рассмотрены в дальнейшем. Ошибки на
этом шаге возникают, когда неверно
интерпретируются требования, не удается
выявить все требующие компромиссных
решений проблемы или приняты неправильные
решения, а также в случае, когда не
сформулированы цели, необходимые, но
не поставленные явно в требованиях
пользователя.
2. Второй процесс
связан с преобразованием целей программы
в ее внешние спецификации, т.е. точное
описание поведения всей системы с точки
зрения пользователя. По объему перевода
это самый сложный шаг в разработке ПО,
поэтому он больше всего подвержен
ошибкам – они бывают и наиболее
серьезными и наиболее многочисленными.
3. Далее следуют
несколько последовательных процессов
перевода – от внешнего описания готового
продукта до получения детального
проекта, описывающего множество
составляющих программу предложений,
выполнение которых должно обеспечить
поведение системы, соответствующее
внешним спецификациям. Сюда включаются
такие процессы, как перевод внешнего
описания в структуру компонент программы
(например, модулей) и перевод каждой из
этих компонент в описание процедурных
шагов (например, в блок-схемы). Поскольку
нам приходится иметь дело со все большими
объемами информации, шансы внесения
ошибок становятся чрезвычайно высокими.
4. Последний процесс
– перевод описания логики программы в
предложения языка программирования.
Хотя на этом шаге часто делается много
ошибок, они обычно незначительные, легко
обнаруживаются и корректируются.
Кроме процессов
перевода имеются и другие источники
ошибок, которые будут кратко рассмотрены
ниже. Однако в данном учебном пособии
мы сосредоточимся на ошибках, возникающих
в четырех вышеназванных процессах
перевода.
В результате работы
над программным проектом возникают как
само ПО, так и документы, описывающие
правила пользования им. Последние обычно
имеют вид печатных руководств или
встроенной в программу помощи и носят
название публикаций. Эти руководства
обычно получаются переводом внешних
спецификаций в материалы, ориентированные
на конкретные группы пользователей.
Публикации
определенным образом влияют на надежность
программного обеспечения. Если при
их подготовке возникает ошибка, то они
не будут точно описывать поведение
программы. Если прочитав руководство,
пользователь начнет работать с программой
и обнаружит, что она ведет себя не так,
как он ожидал, то решит, что это ошибка
в программе, т.е. придет к неправильному
заключению.
Другие источники
ошибок – это неправильное понимание
спецификаций используемой в системе
аппаратуры, базового ПО (операционной
системы), синтаксиса и семантики языка
программирования.
И наконец, при
непосредственном взаимодействии
пользователя с ПО, если слабо разработан
диалог человек – машина (отсутствие
«дружественного интерфейса»),
вероятность ошибки пользователя
увеличивается. Ошибки пользователя же
ставят систему в новые, непредвиденные
обстоятельства, увеличивая таким
образом шансы проявления оставшихся в
программе ошибок.
Эта модель описывает
происхождение большинства ошибок в ПО.
Нередко считается, что ошибки в программе
– это те ошибки, которые делает
программист, когда пишет программу на
языке программирования. Здесь и
проявляется важность модели, поскольку
она более полно описывает причины,
лежащие в основе ненадежности. Благодаря
ей нам стал известен перечень
подлежащих решению задач, способствующих
созданию надежного ПО.
Соседние файлы в папке Надежность
- #
- #
- #
- #
- #
- #

Существует две фундаментальные стратегии: обработка исправимых ошибок (исключения, коды возврата по ошибке, функции-обработчики) и неисправимых (assert(), abort()). В каких случаях какую стратегию лучше использовать?
Виды ошибок
Ошибки возникают по разным причинам: пользователь ввёл странные данные, ОС не может дать вам обработчика файла или код разыменовывает (dereferences) nullptr. Каждая из описанных ошибок требует к себе отдельного подхода. По причинам ошибки делятся на три основные категории:
- Пользовательские ошибки: здесь под пользователем подразумевается человек, сидящий перед компьютером и действительно «использующий» программу, а не какой-то программист, дёргающий ваш API. Такие ошибки возникают тогда, когда пользователь делает что-то неправильно.
- Системные ошибки появляются, когда ОС не может выполнить ваш запрос. Иными словами, причина системных ошибок — сбой вызова системного API. Некоторые возникают потому, что программист передал системному вызову плохие параметры, так что это скорее программистская ошибка, а не системная.
- Программистские ошибки случаются, когда программист не учитывает предварительные условия API или языка программирования. Если API требует, чтобы вы не вызывали
foo()с0в качестве первого параметра, а вы это сделали, — виноват программист. Если пользователь ввёл0, который был переданfoo(), а программист не написал проверку вводимых данных, то это опять же его вина.
Каждая из описанных категорий ошибок требует особого подхода к их обработке.
Пользовательские ошибки
Сделаю очень громкое заявление: такие ошибки — на самом деле не ошибки.
Все пользователи не соблюдают инструкции. Программист, имеющий дело с данными, которые вводят люди, должен ожидать, что вводить будут именно плохие данные. Поэтому первым делом нужно проверять их на валидность, сообщать пользователю об обнаруженных ошибках и просить ввести заново.
Поэтому не имеет смысла применять к пользовательским ошибкам какие-либо стратегии обработки. Вводимые данные нужно как можно скорее проверять, чтобы ошибок не возникало.
Конечно, такое не всегда возможно. Иногда проверять вводимые данные слишком дорого, иногда это не позволяет сделать архитектура кода или разделение ответственности. Но в таких случаях ошибки должны обрабатываться однозначно как исправимые. Иначе, допустим, ваша офисная программа будет падать из-за того, что вы нажали backspace в пустом документе, или ваша игра станет вылетать при попытке выстрелить из разряженного оружия.
Если в качестве стратегии обработки исправимых ошибок вы предпочитаете исключения, то будьте осторожны: исключения предназначены только для исключительных ситуаций, к которым не относится большинство случаев ввода пользователями неверных данных. По сути, это даже норма, по мнению многих приложений. Используйте исключения только тогда, когда пользовательские ошибки обнаруживаются в глубине стека вызовов, вероятно, внешнего кода, когда они возникают редко или проявляются очень жёстко. В противном случае лучше сообщать об ошибках с помощью кодов возврата.
Системные ошибки
Обычно системные ошибки нельзя предсказать. Более того, они недетерминистские и могут возникать в программах, которые до этого работали без нареканий. В отличие от пользовательских ошибок, зависящих исключительно от вводимых данных, системные ошибки — настоящие ошибки.
Но как их обрабатывать, как исправимые или неисправимые?
Это зависит от обстоятельств.
Многие считают, что ошибка нехватки памяти — неисправимая. Зачастую не хватает памяти даже для обработки этой ошибки! И тогда приходится просто сразу же прерывать выполнение.
Но падение программы из-за того, что ОС не может выделить сокет, — это не слишком дружелюбное поведение. Так что лучше бросить исключение и позволить catch аккуратно закрыть программу.
Но бросание исключения — не всегда правильный выбор.
Кто-то даже скажет, что он всегда неправильный.
Если вы хотите повторить операцию после её сбоя, то обёртывание функции в try-catch в цикле — медленное решение. Правильный выбор — возврат кода ошибки и цикличное исполнение, пока не будет возвращено правильное значение.
Если вы создаёте вызов API только для себя, то просто выберите подходящий для своей ситуации путь и следуйте ему. Но если вы пишете библиотеку, то не знаете, чего хотят пользователи. Дальше мы разберём подходящую стратегию для этого случая. Для потенциально неисправимых ошибок подойдёт «обработчик ошибок», а при других ошибках необходимо предоставить два варианта развития событий.
Обратите внимание, что не следует использовать подтверждения (assertions), включающиеся только в режиме отладки. Ведь системные ошибки могут возникать и в релизной сборке!
Программистские ошибки
Это худший вид ошибок. Для их обработки я стараюсь сделать так, чтобы мои ошибки были связаны только с вызовами функций, то есть с плохими параметрами. Прочие типы программистских ошибок могут быть пойманы только в runtime, с помощью отладочных макросов (assertion macros), раскиданных по коду.
При работе с плохими параметрами есть две стратегии: дать им определённое или неопределённое поведение.
Если исходное требование для функции — запрет на передачу ей плохих параметров, то, если их передать, это считается неопределённым поведением и должно проверяться не самой функцией, а оператором вызова (caller). Функция должна делать только отладочное подтверждение (debug assertion).
С другой стороны, если отсутствие плохих параметров не является частью исходных требований, а документация определяет, что функция будет бросать bad_parameter_exception при передаче ей плохого параметра, то передача — это хорошо определённое поведение (бросание исключения или любая другая стратегия обработки исправимых ошибок), и функция всегда должна это проверять.
В качестве примера рассмотрим получающие функции (accessor functions) std::vector<T>operator[] говорится, что индекс должен быть в пределах валидного диапазона, при этом at() сообщает нам, что функция кинет исключение, если индекс не попадает в диапазон. Более того, большинство реализаций стандартных библиотек обеспечивают режим отладки, в котором проверяется индекс operator[], но технически это неопределённое поведение, оно не обязано проверяться.
Примечание: необязательно бросать исключение, чтобы получилось определённое поведение. Пока это не упомянуто в исходных условиях для функции, это считается определённым. Всё, что прописано в исходных условиях, не должно проверяться функцией, это неопределённое поведение.
Когда нужно проверять только с помощью отладочных подтверждений, а когда — постоянно?
К сожалению, однозначного рецепта нет, решение зависит от конкретной ситуации. У меня есть лишь одно проверенное правило, которому я следую при разработке API. Оно основано на наблюдении, что проверять исходные условия должен вызывающий, а не вызываемый. А значит, условие должно быть «проверяемым» для вызывающего. Также условие «проверяемое», если можно легко выполнить операцию, при которой значение параметра всегда будет правильным. Если для параметра это возможно, то это получается исходное условие, а значит, проверяется только посредством отладочного подтверждения (а если слишком дорого, то вообще не проверяется).
Но конечное решение зависит от многих других факторов, так что очень трудно дать какой-то общий совет. По умолчанию я стараюсь свести к неопределённому поведению и использованию только подтверждений. Иногда бывает целесообразно обеспечить оба варианта, как это делает стандартная библиотека с operator[] и at().
Хотя в ряде случаев это может быть ошибкой.
Об иерархии std::exception
Если в качестве стратегии обработки исправимых ошибок вы выбрали исключения, то рекомендуется создать новый класс и наследовать его от одного из классов исключений стандартной библиотеки.
Я предлагаю наследовать только от одного из этих четырёх классов:
std::bad_alloc: для сбоев выделения памяти.std::runtime_error: для общих runtime-ошибок.std::system_error(производное отstd::runtime_error): для системных ошибок с кодами ошибок.std::logic_error: для программистских ошибок с определённым поведением.
Обратите внимание, что в стандартной библиотеке разделяются логические (то есть программистские) и runtime-ошибки. Runtime-ошибки — более широкое определение, чем «системные». Оно описывает «ошибки, обнаруживаемые только при выполнении программы». Такая формулировка не слишком информативна. Лично я использую её для плохих параметров, которые не являются исключительно программистскими ошибками, а могут возникнуть и по вине пользователей. Но это можно определить лишь глубоко в стеке вызовов. Например, плохое форматирование комментариев в standardese приводит к исключению при парсинге, проистекающему из std::runtime_error. Позднее оно ловится на соответствующем уровне и фиксируется в логе. Но я не стал бы использовать этот класс иначе, как и std::logic_error.
Подведём итоги
Есть два пути обработки ошибок:
- как исправимые: используются исключения или возвращаемые значения (в зависимости от ситуации/религии);
- как неисправимые: ошибки журналируются, а программа прерывается.
Подтверждения — это особый вид стратегии обработки неисправимых ошибок, только в режиме отладки.
Есть три основных источника ошибок, каждый требует особого подхода:
- Пользовательские ошибки не должны обрабатываться как ошибки на верхних уровнях программы. Всё, что вводит пользователь, должно проверяться соответствующим образом. Это может обрабатываться как ошибки только на нижних уровнях, которые не взаимодействуют с пользователями напрямую. Применяется стратегия обработки исправимых ошибок.
- Системные ошибки могут обрабатываться в рамках любой из двух стратегий, в зависимости от типа и тяжести. Библиотеки должны работать как можно гибче.
- Программистские ошибки, то есть плохие параметры, могут быть запрещены исходными условиями. В этом случае функция должна использовать только проверку с помощью отладочных подтверждений. Если же речь идёт о полностью определённом поведении, то функции следует предписанным образом сообщать об ошибке. Я стараюсь по умолчанию следовать сценарию с неопределённым поведением и определяю для функции проверку параметров лишь тогда, когда это слишком трудно сделать на стороне вызывающего.
Гибкие методики обработки ошибок в C++
Иногда что-то не работает. Пользователи вводят данные в недопустимом формате, файл не обнаруживается, сетевое соединение сбоит, в системе кончается память. Всё это ошибки, и их надо обрабатывать.
Это относительно легко сделать в высокоуровневых функциях. Вы точно знаете, почему что-то пошло не так, и можете обработать это соответствующим образом. Но в случае с низкоуровневыми функциями всё не так просто. Они не знают, что пошло не так, они знают лишь о самом факте сбоя и должны сообщить об этом тому, кто их вызвал.
В C++ есть два основных подхода: коды возврата ошибок и исключения. Сегодня широко распространено использование исключений. Но некоторые не могут / думают, что не могут / не хотят их использовать — по разным причинам.
Я не буду принимать чью-либо сторону. Вместо этого я опишу методики, которые удовлетворят сторонников обоих подходов. Особенно методики пригодятся разработчикам библиотек.
Проблема
Я работаю над проектом foonathan/memory. Это решение предоставляет различные классы выделения памяти (allocator classes), так что в качестве примера рассмотрим структуру функции выделения.
Для простоты возьмём malloc(). Она возвращает указатель на выделяемую память. Если выделить память не получается, то возвращается nullptr, то есть NULL, то есть ошибочное значение.
У этого решения есть недостатки: вам нужно проверять каждый вызов malloc(). Если вы забудете это сделать, то выделите несуществующую память. Кроме того, по своей натуре коды ошибок транзитивны: если вызвать функцию, которая может вернуть код ошибки, и вы не можете его проигнорировать или обработать, то вы тоже должны вернуть код ошибки.
Это приводит нас к ситуации, когда чередуются нормальные и ошибочные ветви кода. Исключения в таком случае выглядят более подходящим решением. Благодаря им вы сможете обрабатывать ошибки только тогда, когда вам это нужно, а в противном случае — достаточно тихо передать их обратно вызывающему.
Это можно расценить как недостаток.
Но в подобных ситуациях исключения имеют также очень большое преимущество: функция выделения памяти либо возвращает валидную память, либо вообще ничего не возвращает. Это функция «всё или ничего», возвращаемое значение всегда будет валидным. Это полезное следствие согласно принципу Скотта Майера «Make interfaces hard to use incorrectly and easy to use correctly».
Учитывая вышесказанное, можно утверждать, что вам следует использовать исключения в качестве механизма обработки ошибок. Этого мнения придерживается большинство разработчиков на С++, включая и меня. Но проект, которым я занимаюсь, — это библиотека, предоставляющая средства выделения памяти, и предназначена она для приложений, работающих в реальном времени. Для большинства разработчиков подобных приложений (особенно для игроделов) само использование исключений — исключение.
Каламбур детектед.
Чтобы уважить эту группу разработчиков, моей библиотеке лучше обойтись без исключений. Но мне и многим другим они нравятся за элегантность и простоту обработки ошибок, так что ради других разработчиков моей библиотеке лучше использовать исключения.
Так что же делать?
Идеальное решение: возможность включать и отключать исключения по желанию. Но, учитывая природу исключений, нельзя просто менять их местами с кодами ошибок, поскольку у нас не будет внутреннего кода проверки на ошибки — весь внутренний код опирается на предположение о прозрачности исключений. И даже если бы внутри можно было использовать коды ошибок и преобразовывать их в исключения, это лишило бы нас большинства преимуществ последних.
К счастью, я могу определить, что вы делаете, когда обнаруживаете ошибку нехватки памяти: чаще всего вы журналируете это событие и прерываете программу, поскольку она не может корректно работать без памяти. В таких ситуациях исключения — просто способ передачи контроля другой части кода, которая журналирует и прерывает программу. Но есть старый и эффективный способ передачи контроля: указатель функции (function pointer), то есть функция-обработчик (handler function).
Если у вас включены исключения, то вы просто их бросаете. В противном случае вызываете функцию-обработчика и затем прерываете программу. Это предотвратит бесполезную работу функции-обработчика, та позволит программе продолжить выполняться в обычном режиме. Если не прервать, то произойдёт нарушение обязательного постусловия функции: всегда возвращать валидный указатель. Ведь на выполнении этого условия может быть построена работа другого кода, да и вообще это нормальное поведение.
Я называю такой подход обработкой исключений и придерживаюсь его при работе с памятью.
Решение 1: обработчик исключений
Если вам нужно обработать ошибку в условиях, когда наиболее распространённым поведением будет «журналировать и прервать», то можно использовать обработчика исключений. Это такая функция-обработчик, которая вызывается вместо бросания объекта-исключения. Её довольно легко реализовать даже в уже существующем коде. Для этого нужно поместить управление обработкой в класс исключений и обернуть в макрос выражение throw.
Сначала дополним класс и добавим функции для настройки и, возможно, запрашивания функции-обработчика. Я предлагаю делать это так же, как стандартная библиотека обрабатывает std::new_handler:
class my_fatal_error
{
public:
// тип обработчика, он должен брать те же параметры, что и конструктор,
// чтобы у них была одинаковая информация
using handler = void(*)( ... );
// меняет функцию-обработчика
handler set_handler(handler h);
// возвращает текущего обработчика
handler get_handler();
... // нормальное исключение
};Поскольку это входит в область видимости класса исключений, вам не нужно именовать каким-то особым образом. Отлично, нам же легче.
Если исключения включены, то для удаления обработчика можно использовать условное компилирование (conditional compilation). Если хотите, то также напишите обычный подмешанный класс (mixin class), дающий требуемую функциональность.
Конструктор исключений элегантен: он вызывает текущую функцию-обработчика, передавая ей требуемые аргументы из своих параметров. А затем комбинирует с последующим макросом throw:
If```cpp #if EXCEPTIONS #define THROW(Ex) throw (Ex) #else #define THROW(Ex) (Ex), std::abort() #endif> Такой макрос throw также предоставляется [foonathan/compatiblity](https://github.com/foonathan/compatibility).
Можно использовать его и так:
```cpp
THROW(my_fatal_error(...))
Если у вас включена поддержка исключений, то будет создан и брошен объект-исключение, всё как обычно. Но если поддержка выключена, то объект-исключение всё равно будет создан, и — это важно — только после этого произойдёт вызов std::abort(). А поскольку конструктор вызывает функцию-обработчика, то он и работает, как требуется: вы получаете точку настройки для журналирования ошибки. Благодаря же вызову std::abort() после конструктора пользователь не может нарушить постусловие.
Когда я работаю с памятью, то при включённых исключениях у меня также включён и обработчик, который вызывается при бросании исключения.
Так что при этой методике вам ещё будет доступна определённая степень кастомизации, даже если вы отключите исключения. Конечно, замена неполноценная, мы только журналируем и прерываем работу программы, без дальнейшего продолжения. Но в ряде случаев, в том числе при исчерпании памяти, это вполне пригодное решение.
А если я хочу продолжить работу после бросания исключения?
Методика с обработчиком исключений не позволяет этого сделать в связи с постусловием кода. Как же тогда продолжить работу?
Ответ прост — никак. По крайней мере, это нельзя сделать так же просто, как в других случаях. Нельзя просто так вернуть код ошибки вместо исключения, если функция на это не рассчитана.
Есть только одно решение: сделать две функции. Одна возвращает код ошибки, а вторая бросает исключения. Клиенты, которым нужны исключения, будут использовать второй вариант, остальные — первый.
Извините, что говорю такие очевидные вещи, но ради полноты изложения я должен был об этом сказать.
Для примера снова возьмём функцию выделения памяти. В этом случае я использую такие функции:
void* try_malloc(..., int &error_code) noexcept;
void* malloc(...);
При сбое выделения памяти первая версия возвращает nullptr и устанавливает error_code в коде ошибки. Вторая версия не возвращает nullptr, зато бросает исключение. Обратите внимание, что в рамках первой версии очень легко реализовать вторую:
void* malloc(...)
{
auto error_code = 0;
auto res = try_malloc(..., error_code);
if (!res)
throw malloc_error(error_code);
return res;
}Не делайте этого в обратной последовательности, иначе вам придётся ловить исключение, а это дорого. Также это не даст нам скомпилировать код без включённой поддержки исключений. Если сделаете, как показано, то можете просто стереть другую перегрузку (overload) с помощью условного компилирования.
Но даже если у вас включена поддержка исключений, клиенту всё равно может понадобиться вторая версия. Например, когда нужно выделить наибольший возможный объём памяти, как в нашем примере. Будет проще и быстрее вызывать в цикле и проверять по условию, чем ловить исключение.
Решение 2: предоставить две перегрузки
Если недостаточно обработчика исключений, то нужно предоставить две перегрузки. Одна использует код возврата, а вторая бросает исключение.
Если рассматриваемая функция не имеет возвращаемого значения, то можете её использовать для кода ошибки. В противном случае вам придётся возвращать недопустимое значение для сигнализирования об ошибке — как nullptr в вышеприведённом примере, — а также установить выходной параметр для кода ошибки, если хотите предоставить вызывающему дополнительную информацию.
Пожалуйста, не используйте глобальную переменную errno или что-то типа GetLastError()!
Если возвращаемое значение не содержит недопустимое значение для обозначения сбоя, то по мере возможности используйте std::optional или что-то похожее.
Перегрузка исключения (exception overload) может — и должна — быть реализована в рамках версии с кодом ошибки, как это показано выше. Если компилируете без исключений, сотрите перегрузку с помощью условного компилирования.
std::system_error
Подобная система идеально подходит для работы с кодами ошибок в С++ 11.
Она возвращает непортируемый (non-portable) код ошибки std::error_code, то есть возвращаемый функцией операционной системы. С помощью сложной системы библиотечных средств и категорий ошибок вы можете добавить собственные коды ошибок, или портируемые std::error_condition. Для начала почитайте об этом здесь. Если нужно, то можете использовать в функции кода ошибки std::error_code. А для функции исключения есть подходящий класс исключения: std::system_error. Он берёт std::error_code и применяется для передачи этих ошибок в виде исключений.
Эту или подобную систему должны использовать все низкоуровневые функции, являющиеся закрытыми обёртками ОС-функций. Это хорошая — хотя и сложная — альтернатива службе кодов ошибок, предоставляемой операционной системой.
Да, и мне ещё нужно добавить подобное в функции виртуальной памяти. На сегодняшний день они не предоставляют коды ошибок.
std::expected
Выше упоминалось о проблеме, когда у вас нет возвращаемого значения, содержащего недопустимое значение, которое можно использовать для сигнализирования об ошибке. Более того, выходной параметр — не лучший способ получения кода ошибки.
А глобальные переменные вообще не вариант!
В № 4109 предложено решение: std::expected. Это шаблон класса, который также хранит возвращаемое значение или код ошибки. В вышеприведённом примере он мог бы использоваться так:
std::expected<void*, std::error_code> try_malloc(...);
В случае успеха std::expected будет хранить не-null указатель памяти, а при сбое — std::error_code. Сейчас эта методика работает при любых возвращаемых значениях. Комбинация std::expected и функции исключения определённо допускает любые варианты использования.
Заключение
Если вы создаёте библиотеки, то иногда приходится обеспечивать максимальную гибкость использования. Под этим подразумевается и разнообразие средств обработки ошибок: иногда требуются коды возврата, иногда — исключения.
Одна из возможных стратегий — улаживание этих противоречий с помощью обработчика исключений. Просто удостоверьтесь, что когда нужно, то вызывается callback, а не бросается исключение. Это замена для критических ошибок, которая в любом случае будет журналироваться перед прерыванием работы программы. Как таковой этот способ не универсален, вы не можете переключаться в одной программе между двумя версиями. Это лишь обходное решение при отключённой поддержке исключений.
Более гибкий подход — просто предоставить две перегрузки, одну с исключениями, а вторую без. Это даст пользователям максимальную свободу, они смогут выбирать ту версию, что лучше подходит в их ситуации. Недостаток этого подхода: вам придётся больше потрудиться при создании библиотеки.
Аннотация: Попытка классификации ошибок. Сообщение об ошибке с помощью возвращаемого значения. Исключительные ситуации. Обработка исключительных ситуаций, операторы try и catch.
Виды ошибок
Существенной частью любой программы является обработка ошибок.
Прежде чем перейти к описанию средств языка Си++, предназначенных
для обработки ошибок, остановимся немного на том,какие, собственно, ошибки
мы будем рассматривать.
Ошибки компиляции пропустим:пока все они не исправлены,
программа не готова, и запустить ее нельзя. Здесь мы будем рассматривать
только ошибки, происходящие во время выполнения программы.
Первый вид ошибок, который всегда приходит в голову – это ошибки
программирования. Сюда относятся ошибки в алгоритме, в логике
программы и чисто программистские ошибки. Ряд возможных ошибок
мы называли ранее (например, при работе с указателями), но гораздо
больше вы узнаете на собственном горьком опыте.
Теоретически возможно написать программу без таких ошибок. Во
многом язык Си++ помогает предотвратить ошибки во время выполнения
программы,осуществляя строгий контроль на стадии компиляции.
Вообще, чем строже контроль на стадии компиляции, тем меньше ошибок
остается при выполнении программы.
Перечислим некоторые средства языка, которые помогут избежать ошибок:
-
Контроль типов. Случаи использования недопустимых операций
и смешения несовместимых типов будут обнаружены компилятором. - Обязательное объявление имен до их использования. Невозможно
вызвать функцию с неверным числом аргументов. При изменении определения
переменной или функции легко обнаружить все места, где она
используется. - Ограничение видимости имен, контексты имен. Уменьшается возможность
конфликтов имен, неправильного переопределения имен.
Самым важным средством уменьшения вероятности ошибок является
объектно-ориентированный подход к программированию, который поддерживает
язык Си++. Наряду с преимуществами объектного программирования,
о которых мы говорили ранее, построение программы из классов позволяет
отлаживать классы по отдельности и строить программы из надежных
составных «кирпичиков», используя одни и те же классы многократно.
Несмотря на все эти положительные качества языка, остается «простор»
для написания ошибочных программ. По мере рассмотрения
свойств языка, мы стараемся давать рекомендации, какие возможности
использовать, чтобы уменьшить вероятность ошибки.
Лучше исходить из того, что идеальных программ не существует, это
помогает разрабатывать более надежные программы. Самое главное –
обеспечить контроль данных, а для этого необходимо проверять в программе
все, что может содержать ошибку. Если в программе предполагается
какое-то условие, желательно проверить его, хотя бы в начальной
версии программы, до того, как можно будет на опыте убедиться, что это
условие действительно выполняется. Важно также проверять указатели,
передаваемые в качестве аргументов, на равенство нулю; проверять, не
выходят ли индексы за границы массива и т.п.
Ну и решающими качествами, позволяющими уменьшить количество ошибок,
являются внимательность, аккуратность и опыт.
Второй вид ошибок – «предусмотренные», запланированные ошибки.
Если разрабатывается программа диалога с пользователем, такая
программа обязана адекватно реагировать и обрабатывать неправильные
нажатия клавиш. Программа чтения текста должна учитывать возможные
синтаксические ошибки. Программа передачи данных по телефонной линии
должна обрабатывать помехи и возможные сбои при передаче. Такие ошибки – это, вообще говоря, не ошибки с точки зрения программы, а
плановые ситуации, которые она обрабатывает.
Третий вид ошибок тоже в какой-то мере предусмотрен. Это исключительные
ситуации, которые могут иметь место, даже если в программе
нет ошибок . Например, нехватка памяти для создания нового объекта.
Или сбой диска при извлечении информации из базы данных.
Именно обработка двух последних видов ошибок и рассматривается в последующих
разделах. Граница между ними довольно условна. Например,
для большинства программ сбой диска – исключительная ситуация, но
для операционной системы сбой диска должен быть предусмотрен и должен
обрабатываться. Скорее два типа можно разграничить по тому, какая
реакция программы должна быть предусмотрена. Если после плановых ошибок программа должна продолжать работать, то после исключительных
ситуаций надо лишь сохранить уже вычисленные данные и завершить программу.
Возвращаемое значение как признак ошибки
Простейший способ сообщения об ошибках предполагает использование возвращаемого значения функции или метода. Функция сохранения
объекта в базе данных может возвращать логическое значение: true в
случае успешного сохранения, false – в случае ошибки.
class Database
{
public:
bool SaveObject(const Object& obj);
};
Соответственно, вызов метода должен выглядеть так:
if (database.SaveObject(my_obj) == false ){
//обработка ошибки
}
Обработка ошибки, разумеется, зависит от конкретной программы.
Типична ситуация, когда при многократно вложенных вызовах функций
обработка происходит на несколько уровней выше, чем уровень, где ошибка произошла. В таком случае результат, сигнализирующий об ошибке,
придется передавать во всех вложенных вызовах.
int main()
{
if (fun1()==false ) //обработка ошибки
return 1;
}
bool
fun1()
{
if (fun2()==false )
return false ;
return true ;
}
bool
fun2()
{
if (database.SaveObject(obj)==false )
return false ;
return true ;
}
Если функция или метод должны возвращать какую-то величину в качестве
результата, то особое, недопустимое, значение этой величины используется в
качестве признака ошибки. Если метод возвращает указатель,
выдача нулевого указателя применяется в качестве признака ошибки. Если
функция вычисляет положительное число, возврат — 1 можно использовать
в качестве признака ошибки.
Иногда невозможно вернуть признак ошибки в качестве возвращаемого значения.
Примером является конструктор объекта, который не может вернуть значение. Как же сообщить о том, что во время инициализации объекта что-то было не так?
Распространенным решением является дополнительный атрибут
объекта – флаг, отражающий состояние объекта. Предположим, конструктор
класса Database должен соединиться с сервером базы данных.
class Database
{
public :
Database(const char *serverName);
...
bool Ok(void) const {return okFlag;};
private :
bool okFlag;
};
Database::Database(const char*serverName)
{
if (connect(serverName)==true )
okFlag =true ;
else
okFlag =false ;
}
int main()
{
Database database("db-server");
if (!database.Ok()){
cerr <<"Ошибка соединения с базой данных"<<endl;
return 0;
}
return 1;
}
Лучше вместо метода Ok, возвращающего значение флага okFlag,
переопределить операцию ! (отрицание).
class Database
{
public :
bool operator !()const {return !okFlag;};
};
Тогда проверка успешности соединения с базой данных будет выглядеть так:
if (!database){
cerr <<"Ошибка соединения с базой
данных"<<endl;
}
Следует отметить, что лучше избегать такого построения классов,
при котором возможны ошибки в конструкторе. Из конструктора можно
выделить соединение с сервером базы данных в отдельный метод Open:
class Database
{
public :
Database();
bool Open(const char*serverName);
}
и тогда отпадает необходимость в операции ! или методе Ok().
Использование возвращаемого значения в качестве признака ошибки –
метод почти универсальный. Он применяется, прежде всего, для обработки
запланированных ошибочных ситуаций. Этот метод имеет ряд
недостатков. Во-первых, приходится передавать признак ошибки через
вложенные вызовы функций. Во-вторых, возникают неудобства, если
метод или функция уже возвращают значение, и приходится либо модифицировать
интерфейс, либо придумывать специальное » ошибочное »
значение. В-третьих, логика программы оказывается запутанной из-за
сплошных условных операторов if с проверкой на ошибочное значение.
A software bug is an error, flaw or fault in the design, development, or operation of computer software that causes it to produce an incorrect or unexpected result, or to behave in unintended ways. The process of finding and correcting bugs is termed «debugging» and often uses formal techniques or tools to pinpoint bugs. Since the 1950s, some computer systems have been designed to deter, detect or auto-correct various computer bugs during operations.
Bugs in software can arise from mistakes and errors made in interpreting and extracting users’ requirements, planning a program’s design, writing its source code, and from interaction with humans, hardware and programs, such as operating systems or libraries. A program with many, or serious, bugs is often described as buggy. Bugs can trigger errors that may have ripple effects. The effects of bugs may be subtle, such as unintended text formatting, through to more obvious effects such as causing a program to crash, freezing the computer, or causing damage to hardware. Other bugs qualify as security bugs and might, for example, enable a malicious user to bypass access controls in order to obtain unauthorized privileges.[1]
Some software bugs have been linked to disasters. Bugs in code that controlled the Therac-25 radiation therapy machine were directly responsible for patient deaths in the 1980s. In 1996, the European Space Agency’s US$1 billion prototype Ariane 5 rocket was destroyed less than a minute after launch due to a bug in the on-board guidance computer program.[2] In 1994, an RAF Chinook helicopter crashed, killing 29; this was initially blamed on pilot error, but was later thought to have been caused by a software bug in the engine-control computer.[3] Buggy software caused the early 21st century British Post Office scandal, the most widespread miscarriage of justice in British legal history.[4]
In 2002, a study commissioned by the US Department of Commerce’s National Institute of Standards and Technology concluded that «software bugs, or errors, are so prevalent and so detrimental that they cost the US economy an estimated $59 billion annually, or about 0.6 percent of the gross domestic product».[5]
History[edit]
The Middle English word bugge is the basis for the terms «bugbear» and «bugaboo» as terms used for a monster.[6]
The term «bug» to describe defects has been a part of engineering jargon since the 1870s[7] and predates electronics and computers; it may have originally been used in hardware engineering to describe mechanical malfunctions. For instance, Thomas Edison wrote in a letter to an associate in 1878:[8]
… difficulties arise—this thing gives out and [it is] then that «Bugs»—as such little faults and difficulties are called—show themselves[9]
Baffle Ball, the first mechanical pinball game, was advertised as being «free of bugs» in 1931.[10] Problems with military gear during World War II were referred to as bugs (or glitches).[11] In a book published in 1942, Louise Dickinson Rich, speaking of a powered ice cutting machine, said, «Ice sawing was suspended until the creator could be brought in to take the bugs out of his darling.»[12]
Isaac Asimov used the term «bug» to relate to issues with a robot in his short story «Catch That Rabbit», published in 1944.

A page from the Harvard Mark II electromechanical computer’s log, featuring a dead moth that was removed from the device.
The term «bug» was used in an account by computer pioneer Grace Hopper, who publicized the cause of a malfunction in an early electromechanical computer.[13] A typical version of the story is:
In 1946, when Hopper was released from active duty, she joined the Harvard Faculty at the Computation Laboratory where she continued her work on the Mark II and Mark III. Operators traced an error in the Mark II to a moth trapped in a relay, coining the term bug. This bug was carefully removed and taped to the log book. Stemming from the first bug, today we call errors or glitches in a program a bug.[14]
Hopper was not present when the bug was found, but it became one of her favorite stories.[15] The date in the log book was September 9, 1947.[16][17][18] The operators who found it, including William «Bill» Burke, later of the Naval Weapons Laboratory, Dahlgren, Virginia,[19] were familiar with the engineering term and amusedly kept the insect with the notation «First actual case of bug being found.» This log book, complete with attached moth, is part of the collection of the Smithsonian National Museum of American History.[17]
The related term «debug» also appears to predate its usage in computing: the Oxford English Dictionary‘s etymology of the word contains an attestation from 1945, in the context of aircraft engines.[20]
The concept that software might contain errors dates back to Ada Lovelace’s 1843 notes on the analytical engine, in which she speaks of the possibility of program «cards» for Charles Babbage’s analytical engine being erroneous:
… an analysing process must equally have been performed in order to furnish the Analytical Engine with the necessary operative data; and that herein may also lie a possible source of error. Granted that the actual mechanism is unerring in its processes, the cards may give it wrong orders.
«Bugs in the System» report[edit]
The Open Technology Institute, run by the group, New America,[21] released a report «Bugs in the System» in August 2016 stating that U.S. policymakers should make reforms to help researchers identify and address software bugs. The report «highlights the need for reform in the field of software vulnerability discovery and disclosure.»[22] One of the report’s authors said that Congress has not done enough to address cyber software vulnerability, even though Congress has passed a number of bills to combat the larger issue of cyber security.[22]
Government researchers, companies, and cyber security experts are the people who typically discover software flaws. The report calls for reforming computer crime and copyright laws.[22]
The Computer Fraud and Abuse Act, the Digital Millennium Copyright Act and the Electronic Communications Privacy Act criminalize and create civil penalties for actions that security researchers routinely engage in while conducting legitimate security research, the report said.[22]
Terminology[edit]
While the use of the term «bug» to describe software errors is common, many have suggested that it should be abandoned. One argument is that the word «bug» is divorced from a sense that a human being caused the problem, and instead implies that the defect arose on its own, leading to a push to abandon the term «bug» in favor of terms such as «defect», with limited success.[23] Since the 1970s Gary Kildall somewhat humorously suggested to use the term «blunder».[24][25]
In software engineering, mistake metamorphism (from Greek meta = «change», morph = «form») refers to the evolution of a defect in the final stage of software deployment. Transformation of a «mistake» committed by an analyst in the early stages of the software development lifecycle, which leads to a «defect» in the final stage of the cycle has been called ‘mistake metamorphism’.[26]
Different stages of a «mistake» in the entire cycle may be described as «mistakes», «anomalies», «faults», «failures», «errors», «exceptions», «crashes», «glitches», «bugs», «defects», «incidents», or «side effects».[26]
Prevention[edit]

The software industry has put much effort into reducing bug counts.[27][28] These include:
Typographical errors[edit]
Bugs usually appear when the programmer makes a logic error. Various innovations in programming style and defensive programming are designed to make these bugs less likely, or easier to spot. Some typos, especially of symbols or logical/mathematical operators, allow the program to operate incorrectly, while others such as a missing symbol or misspelled name may prevent the program from operating. Compiled languages can reveal some typos when the source code is compiled.
Development methodologies[edit]
Several schemes assist managing programmer activity so that fewer bugs are produced. Software engineering (which addresses software design issues as well) applies many techniques to prevent defects. For example, formal program specifications state the exact behavior of programs so that design bugs may be eliminated. Unfortunately, formal specifications are impractical for anything but the shortest programs, because of problems of combinatorial explosion and indeterminacy.
Unit testing involves writing a test for every function (unit) that a program is to perform.
In test-driven development unit tests are written before the code and the code is not considered complete until all tests complete successfully.
Agile software development involves frequent software releases with relatively small changes. Defects are revealed by user feedback.
Open source development allows anyone to examine source code. A school of thought popularized by Eric S. Raymond as Linus’s law says that popular open-source software has more chance of having few or no bugs than other software, because «given enough eyeballs, all bugs are shallow».[29] This assertion has been disputed, however: computer security specialist Elias Levy wrote that «it is easy to hide vulnerabilities in complex, little understood and undocumented source code,» because, «even if people are reviewing the code, that doesn’t mean they’re qualified to do so.»[30] An example of an open-source software bug was the 2008 OpenSSL vulnerability in Debian.
Programming language support[edit]
Programming languages include features to help prevent bugs, such as static type systems, restricted namespaces and modular programming. For example, when a programmer writes (pseudocode) LET REAL_VALUE PI = "THREE AND A BIT", although this may be syntactically correct, the code fails a type check. Compiled languages catch this without having to run the program. Interpreted languages catch such errors at runtime. Some languages deliberately exclude features that easily lead to bugs, at the expense of slower performance: the general principle being that, it is almost always better to write simpler, slower code than inscrutable code that runs slightly faster, especially considering that maintenance cost is substantial. For example, the Java programming language does not support pointer arithmetic; implementations of some languages such as Pascal and scripting languages often have runtime bounds checking of arrays, at least in a debugging build.
Code analysis[edit]
Tools for code analysis help developers by inspecting the program text beyond the compiler’s capabilities to spot potential problems. Although in general the problem of finding all programming errors given a specification is not solvable (see halting problem), these tools exploit the fact that human programmers tend to make certain kinds of simple mistakes often when writing software.
Instrumentation[edit]
Tools to monitor the performance of the software as it is running, either specifically to find problems such as bottlenecks or to give assurance as to correct working, may be embedded in the code explicitly (perhaps as simple as a statement saying PRINT "I AM HERE"), or provided as tools. It is often a surprise to find where most of the time is taken by a piece of code, and this removal of assumptions might cause the code to be rewritten.
Testing[edit]
Software testers are people whose primary task is to find bugs, or write code to support testing. On some projects, more resources may be spent on testing than in developing the program.
Measurements during testing can provide an estimate of the number of likely bugs remaining; this becomes more reliable the longer a product is tested and developed.[citation needed]
Debugging[edit]
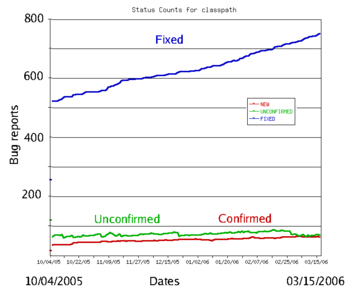
The typical bug history (GNU Classpath project data). A new bug submitted by the user is unconfirmed. Once it has been reproduced by a developer, it is a confirmed bug. The confirmed bugs are later fixed. Bugs belonging to other categories (unreproducible, will not be fixed, etc.) are usually in the minority
Finding and fixing bugs, or debugging, is a major part of computer programming. Maurice Wilkes, an early computing pioneer, described his realization in the late 1940s that much of the rest of his life would be spent finding mistakes in his own programs.[31]
Usually, the most difficult part of debugging is finding the bug. Once it is found, correcting it is usually relatively easy. Programs known as debuggers help programmers locate bugs by executing code line by line, watching variable values, and other features to observe program behavior. Without a debugger, code may be added so that messages or values may be written to a console or to a window or log file to trace program execution or show values.
However, even with the aid of a debugger, locating bugs is something of an art. It is not uncommon for a bug in one section of a program to cause failures in a completely different section,[citation needed] thus making it especially difficult to track (for example, an error in a graphics rendering routine causing a file I/O routine to fail), in an apparently unrelated part of the system.
Sometimes, a bug is not an isolated flaw, but represents an error of thinking or planning on the part of the programmer. Such logic errors require a section of the program to be overhauled or rewritten. As a part of code review, stepping through the code and imagining or transcribing the execution process may often find errors without ever reproducing the bug as such.
More typically, the first step in locating a bug is to reproduce it reliably. Once the bug is reproducible, the programmer may use a debugger or other tool while reproducing the error to find the point at which the program went astray.
Some bugs are revealed by inputs that may be difficult for the programmer to re-create. One cause of the Therac-25 radiation machine deaths was a bug (specifically, a race condition) that occurred only when the machine operator very rapidly entered a treatment plan; it took days of practice to become able to do this, so the bug did not manifest in testing or when the manufacturer attempted to duplicate it. Other bugs may stop occurring whenever the setup is augmented to help find the bug, such as running the program with a debugger; these are called heisenbugs (humorously named after the Heisenberg uncertainty principle).
Since the 1990s, particularly following the Ariane 5 Flight 501 disaster, interest in automated aids to debugging rose, such as static code analysis by abstract interpretation.[32]
Some classes of bugs have nothing to do with the code. Faulty documentation or hardware may lead to problems in system use, even though the code matches the documentation. In some cases, changes to the code eliminate the problem even though the code then no longer matches the documentation. Embedded systems frequently work around hardware bugs, since to make a new version of a ROM is much cheaper than remanufacturing the hardware, especially if they are commodity items.
Benchmark of bugs[edit]
To facilitate reproducible research on testing and debugging, researchers use curated benchmarks of bugs:
- the Siemens benchmark
- ManyBugs[33] is a benchmark of 185 C bugs in nine open-source programs.
- Defects4J[34] is a benchmark of 341 Java bugs from 5 open-source projects. It contains the corresponding patches, which cover a variety of patch type.
Bug management[edit]
Bug management includes the process of documenting, categorizing, assigning, reproducing, correcting and releasing the corrected code. Proposed changes to software – bugs as well as enhancement requests and even entire releases – are commonly tracked and managed using bug tracking systems or issue tracking systems.[35] The items added may be called defects, tickets, issues, or, following the agile development paradigm, stories and epics. Categories may be objective, subjective or a combination, such as version number, area of the software, severity and priority, as well as what type of issue it is, such as a feature request or a bug.
A bug triage reviews bugs and decides whether and when to fix them. The decision is based on the bug’s priority, and factors such as project schedules. The triage is not meant to investigate the cause of bugs, but rather the cost of fixing them. The triage happens regularly, and goes through bugs opened or reopened since the previous meeting. The attendees of the triage process typically are the project manager, development manager, test manager, build manager, and technical experts.[36][37]
Severity[edit]
Severity is the intensity of the impact the bug has on system operation.[38] This impact may be data loss, financial, loss of goodwill and wasted effort. Severity levels are not standardized. Impacts differ across industry. A crash in a video game has a totally different impact than a crash in a web browser, or real time monitoring system. For example, bug severity levels might be «crash or hang», «no workaround» (meaning there is no way the customer can accomplish a given task), «has workaround» (meaning the user can still accomplish the task), «visual defect» (for example, a missing image or displaced button or form element), or «documentation error». Some software publishers use more qualified severities such as «critical», «high», «low», «blocker» or «trivial».[39] The severity of a bug may be a separate category to its priority for fixing, and the two may be quantified and managed separately.
Priority[edit]
Priority controls where a bug falls on the list of planned changes. The priority is decided by each software producer. Priorities may be numerical, such as 1 through 5, or named, such as «critical», «high», «low», or «deferred». These rating scales may be similar or even identical to severity ratings, but are evaluated as a combination of the bug’s severity with its estimated effort to fix; a bug with low severity but easy to fix may get a higher priority than a bug with moderate severity that requires excessive effort to fix. Priority ratings may be aligned with product releases, such as «critical» priority indicating all the bugs that must be fixed before the next software release.
A bug severe enough to delay or halt the release of the product is called a «show stopper»[40] or «showstopper bug».[41] It is named so because it «stops the show» – causes unacceptable product failure.[41]
Software releases[edit]
It is common practice to release software with known, low-priority bugs. Bugs of sufficiently high priority may warrant a special release of part of the code containing only modules with those fixes. These are known as patches. Most releases include a mixture of behavior changes and multiple bug fixes. Releases that emphasize bug fixes are known as maintenance releases, to differentiate it from major releases that emphasize feature additions or changes.
Reasons that a software publisher opts not to patch or even fix a particular bug include:
- A deadline must be met and resources are insufficient to fix all bugs by the deadline.[42]
- The bug is already fixed in an upcoming release, and it is not of high priority.
- The changes required to fix the bug are too costly or affect too many other components, requiring a major testing activity.
- It may be suspected, or known, that some users are relying on the existing buggy behavior; a proposed fix may introduce a breaking change.
- The problem is in an area that will be obsolete with an upcoming release; fixing it is unnecessary.
- «It’s not a bug, it’s a feature».[43] A misunderstanding has arisen between expected and perceived behavior or undocumented feature.
Types[edit]
In software development projects, a mistake or error may be introduced at any stage. Bugs arise from oversight or misunderstanding by a software team during specification, design, coding, configuration, data entry or documentation. For example, a relatively simple program to alphabetize a list of words, the design might fail to consider what should happen when a word contains a hyphen. Or when converting an abstract design into code, the coder might inadvertently create an off-by-one error which can be a «<» where «<=» was intended, and fail to sort the last word in a list.
Another category of bug is called a race condition that may occur when programs have multiple components executing at the same time. If the components interact in a different order than the developer intended, they could interfere with each other and stop the program from completing its tasks. These bugs may be difficult to detect or anticipate, since they may not occur during every execution of a program.
Conceptual errors are a developer’s misunderstanding of what the software must do. The resulting software may perform according to the developer’s understanding, but not what is really needed. Other types:
Arithmetic[edit]
In operations on numerical values, problems can arise that result in unexpected output, slowing of a process, or crashing.[44] These can be from a lack of awareness of the qualities of the data storage such as a loss of precision due to rounding, numerically unstable algorithms, arithmetic overflow and underflow, or from lack of awareness of how calculations are handled by different software coding languages such as division by zero which in some languages may throw an exception, and in others may return a special value such as NaN or infinity.
Control flow[edit]
Control flow bugs are those found in processes with valid logic, but that lead to unintended results, such as infinite loops and infinite recursion, incorrect comparisons for conditional statements such as using the incorrect comparison operator, and off-by-one errors (counting one too many or one too few iterations when looping).
Interfacing[edit]
- Incorrect API usage.
- Incorrect protocol implementation.
- Incorrect hardware handling.
- Incorrect assumptions of a particular platform.
- Incompatible systems. A new API or communications protocol may seem to work when two systems use different versions, but errors may occur when a function or feature implemented in one version is changed or missing in another. In production systems which must run continually, shutting down the entire system for a major update may not be possible, such as in the telecommunication industry[45] or the internet.[46][47][48] In this case, smaller segments of a large system are upgraded individually, to minimize disruption to a large network. However, some sections could be overlooked and not upgraded, and cause compatibility errors which may be difficult to find and repair.
- Incorrect code annotations.
Concurrency[edit]
- Deadlock, where task A cannot continue until task B finishes, but at the same time, task B cannot continue until task A finishes.
- Race condition, where the computer does not perform tasks in the order the programmer intended.
- Concurrency errors in critical sections, mutual exclusions and other features of concurrent processing. Time-of-check-to-time-of-use (TOCTOU) is a form of unprotected critical section.
Resourcing[edit]
- Null pointer dereference.
- Using an uninitialized variable.
- Using an otherwise valid instruction on the wrong data type (see packed decimal/binary-coded decimal).
- Access violations.
- Resource leaks, where a finite system resource (such as memory or file handles) become exhausted by repeated allocation without release.
- Buffer overflow, in which a program tries to store data past the end of allocated storage. This may or may not lead to an access violation or storage violation. These are frequently security bugs.
- Excessive recursion which—though logically valid—causes stack overflow.
- Use-after-free error, where a pointer is used after the system has freed the memory it references.
- Double free error.
Syntax[edit]
- Use of the wrong token, such as performing assignment instead of equality test. For example, in some languages x=5 will set the value of x to 5 while x==5 will check whether x is currently 5 or some other number. Interpreted languages allow such code to fail. Compiled languages can catch such errors before testing begins.
Teamwork[edit]
- Unpropagated updates; e.g. programmer changes «myAdd» but forgets to change «mySubtract», which uses the same algorithm. These errors are mitigated by the Don’t Repeat Yourself philosophy.
- Comments out of date or incorrect: many programmers assume the comments accurately describe the code.
- Differences between documentation and product.
Implications[edit]
The amount and type of damage a software bug may cause naturally affects decision-making, processes and policy regarding software quality. In applications such as human spaceflight, aviation, nuclear power, health care, public transport or automotive safety, since software flaws have the potential to cause human injury or even death, such software will have far more scrutiny and quality control than, for example, an online shopping website. In applications such as banking, where software flaws have the potential to cause serious financial damage to a bank or its customers, quality control is also more important than, say, a photo editing application.
Other than the damage caused by bugs, some of their cost is due to the effort invested in fixing them. In 1978, Lientz et al. showed that the median of projects invest 17 percent of the development effort in bug fixing.[49] In 2020, research on GitHub repositories showed the median is 20%.[50]
Residual bugs in delivered product[edit]
In 1994, NASA’s Goddard Space Flight Center managed to reduce their average number of errors from 4.5 per 1000 lines of code (SLOC) down to 1 per 1000 SLOC.[51]
Another study in 1990 reported that exceptionally good software development processes can achieve deployment failure rates as low as 0.1 per 1000 SLOC.[52] This figure is iterated in literature such as Code Complete by Steve McConnell,[53] and the NASA study on Flight Software Complexity.[54] Some projects even attained zero defects: the firmware in the IBM Wheelwriter typewriter which consists of 63,000 SLOC, and the Space Shuttle software with 500,000 SLOC.[52]
Well-known bugs[edit]
A number of software bugs have become well-known, usually due to their severity: examples include various space and military aircraft crashes. Possibly the most famous bug is the Year 2000 problem or Y2K bug, which caused many programs written long before the transition from 19xx to 20xx dates to malfunction, for example treating a date such as «25 Dec 04» as being in 1904, displaying «19100» instead of «2000», and so on. A huge effort at the end of the 20th century resolved the most severe problems, and there were no major consequences.
The 2012 stock trading disruption involved one such incompatibility between the old API and a new API.
In popular culture[edit]
- In both the 1968 novel 2001: A Space Odyssey and the corresponding 1968 film 2001: A Space Odyssey, a spaceship’s onboard computer, HAL 9000, attempts to kill all its crew members. In the follow-up 1982 novel, 2010: Odyssey Two, and the accompanying 1984 film, 2010, it is revealed that this action was caused by the computer having been programmed with two conflicting objectives: to fully disclose all its information, and to keep the true purpose of the flight secret from the crew; this conflict caused HAL to become paranoid and eventually homicidal.
- In the English version of the Nena 1983 song 99 Luftballons (99 Red Balloons) as a result of «bugs in the software», a release of a group of 99 red balloons are mistaken for an enemy nuclear missile launch, requiring an equivalent launch response, resulting in catastrophe.
- In the 1999 American comedy Office Space, three employees attempt (unsuccessfully) to exploit their company’s preoccupation with the Y2K computer bug using a computer virus that sends rounded-off fractions of a penny to their bank account—a long-known technique described as salami slicing.
- The 2004 novel The Bug, by Ellen Ullman, is about a programmer’s attempt to find an elusive bug in a database application.[55]
- The 2008 Canadian film Control Alt Delete is about a computer programmer at the end of 1999 struggling to fix bugs at his company related to the year 2000 problem.
See also[edit]
- Anti-pattern
- Bug bounty program
- Glitch removal
- Hardware bug
- ISO/IEC 9126, which classifies a bug as either a defect or a nonconformity
- Orthogonal Defect Classification
- Racetrack problem
- RISKS Digest
- Software defect indicator
- Software regression
- Software rot
- Automatic bug fixing
References[edit]
- ^ Mittal, Varun; Aditya, Shivam (January 1, 2015). «Recent Developments in the Field of Bug Fixing». Procedia Computer Science. International Conference on Computer, Communication and Convergence (ICCC 2015). 48: 288–297. doi:10.1016/j.procs.2015.04.184. ISSN 1877-0509.
- ^ «Ariane 501 — Presentation of Inquiry Board report». www.esa.int. Retrieved January 29, 2022.
- ^ Prof. Simon Rogerson. «The Chinook Helicopter Disaster». Ccsr.cse.dmu.ac.uk. Archived from the original on July 17, 2012. Retrieved September 24, 2012.
- ^ «Post Office scandal ruined lives, inquiry hears». BBC News. February 14, 2022.
- ^ «Software bugs cost US economy dear». June 10, 2009. Archived from the original on June 10, 2009. Retrieved September 24, 2012.
{{cite web}}: CS1 maint: unfit URL (link) - ^ Computerworld staff (September 3, 2011). «Moth in the machine: Debugging the origins of ‘bug’«. Computerworld. Archived from the original on August 25, 2015.
- ^ «bug». Oxford English Dictionary (Online ed.). Oxford University Press. (Subscription or participating institution membership required.) 5a
- ^ «Did You Know? Edison Coined the Term «Bug»«. August 1, 2013. Retrieved July 19, 2019.
- ^ Edison to Puskas, 13 November 1878, Edison papers, Edison National Laboratory, U.S. National Park Service, West Orange, N.J., cited in Hughes, Thomas Parke (1989). American Genesis: A Century of Invention and Technological Enthusiasm, 1870-1970. Penguin Books. p. 75. ISBN 978-0-14-009741-2.
- ^ «Baffle Ball». Internet Pinball Database.
(See image of advertisement in reference entry)
- ^ «Modern Aircraft Carriers are Result of 20 Years of Smart Experimentation». Life. June 29, 1942. p. 25. Archived from the original on June 4, 2013. Retrieved November 17, 2011.
- ^ Dickinson Rich, Louise (1942), We Took to the Woods, JB Lippincott Co, p. 93, LCCN 42024308, OCLC 405243, archived from the original on March 16, 2017.
- ^ FCAT NRT Test, Harcourt, March 18, 2008
- ^ «Danis, Sharron Ann: «Rear Admiral Grace Murray Hopper»«. ei.cs.vt.edu. February 16, 1997. Retrieved January 31, 2010.
- ^ James S. Huggins. «First Computer Bug». Jamesshuggins.com. Archived from the original on August 16, 2000. Retrieved September 24, 2012.
- ^ «Bug Archived March 23, 2017, at the Wayback Machine», The Jargon File, ver. 4.4.7. Retrieved June 3, 2010.
- ^ a b «Log Book With Computer Bug Archived March 23, 2017, at the Wayback Machine», National Museum of American History, Smithsonian Institution.
- ^ «The First «Computer Bug», Naval Historical Center. But note the Harvard Mark II computer was not complete until the summer of 1947.
- ^ IEEE Annals of the History of Computing, Vol 22 Issue 1, 2000
- ^ Journal of the Royal Aeronautical Society. 49, 183/2, 1945 «It ranged … through the stage of type test and flight test and ‘debugging’ …»
- ^ Wilson, Andi; Schulman, Ross; Bankston, Kevin; Herr, Trey. «Bugs in the System» (PDF). Open Policy Institute. Archived (PDF) from the original on September 21, 2016. Retrieved August 22, 2016.
- ^ a b c d Rozens, Tracy (August 12, 2016). «Cyber reforms needed to strengthen software bug discovery and disclosure: New America report – Homeland Preparedness News». Retrieved August 23, 2016.
- ^ «News at SEI 1999 Archive». cmu.edu. Archived from the original on May 26, 2013.
- ^ Shustek, Len (August 2, 2016). «In His Own Words: Gary Kildall». Remarkable People. Computer History Museum. Archived from the original on December 17, 2016.
- ^ Kildall, Gary Arlen (August 2, 2016) [1993]. Kildall, Scott; Kildall, Kristin (eds.). «Computer Connections: People, Places, and Events in the Evolution of the Personal Computer Industry» (Manuscript, part 1). Kildall Family: 14–15. Archived from the original on November 17, 2016. Retrieved November 17, 2016.
- ^ a b «Testing experience : te : the magazine for professional testers». Testing Experience. Germany: testingexperience: 42. March 2012. ISSN 1866-5705. (subscription required)
- ^ Huizinga, Dorota; Kolawa, Adam (2007). Automated Defect Prevention: Best Practices in Software Management. Wiley-IEEE Computer Society Press. p. 426. ISBN 978-0-470-04212-0. Archived from the original on April 25, 2012.
- ^ McDonald, Marc; Musson, Robert; Smith, Ross (2007). The Practical Guide to Defect Prevention. Microsoft Press. p. 480. ISBN 978-0-7356-2253-1.
- ^ «Release Early, Release Often» Archived May 14, 2011, at the Wayback Machine, Eric S. Raymond, The Cathedral and the Bazaar
- ^ «Wide Open Source» Archived September 29, 2007, at the Wayback Machine, Elias Levy, SecurityFocus, April 17, 2000
- ^ Maurice Wilkes Quotes
- ^ «PolySpace Technologies history». christele.faure.pagesperso-orange.fr. Retrieved August 1, 2019.
- ^ Le Goues, Claire; Holtschulte, Neal; Smith, Edward K.; Brun, Yuriy; Devanbu, Premkumar; Forrest, Stephanie; Weimer, Westley (2015). «The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs». IEEE Transactions on Software Engineering. 41 (12): 1236–1256. doi:10.1109/TSE.2015.2454513. ISSN 0098-5589.
- ^ Just, René; Jalali, Darioush; Ernst, Michael D. (2014). «Defects4J: a database of existing faults to enable controlled testing studies for Java programs». Proceedings of the 2014 International Symposium on Software Testing and Analysis — ISSTA 2014. pp. 437–440. CiteSeerX 10.1.1.646.3086. doi:10.1145/2610384.2628055. ISBN 9781450326452. S2CID 12796895.
- ^ Allen, Mitch (May–June 2002). «Bug Tracking Basics: A beginner’s guide to reporting and tracking defects». Software Testing & Quality Engineering Magazine. Vol. 4, no. 3. pp. 20–24. Retrieved December 19, 2017.
- ^ Rex Black (2002). Managing The Testing Process (2Nd Ed.). Wiley India Pvt. Limited. p. 139. ISBN 9788126503131. Retrieved June 19, 2021.
- ^ Chris Vander Mey (August 24, 2012). Shipping Greatness — Practical Lessons on Building and Launching Outstanding Software, Learned on the Job at Google and Amazon. O’Reilly Media. pp. 79–81. ISBN 9781449336608.
- ^ Soleimani Neysiani, Behzad; Babamir, Seyed Morteza; Aritsugi, Masayoshi (October 1, 2020). «Efficient feature extraction model for validation performance improvement of duplicate bug report detection in software bug triage systems». Information and Software Technology. 126: 106344. doi:10.1016/j.infsof.2020.106344. S2CID 219733047.
- ^ «5.3. Anatomy of a Bug». bugzilla.org. Archived from the original on May 23, 2013.
- ^ Jones, Wilbur D. Jr., ed. (1989). «Show stopper». Glossary: defense acquisition acronyms and terms (4 ed.). Fort Belvoir, Virginia, USA: Department of Defense, Defense Systems Management College. p. 123. hdl:2027/mdp.39015061290758 – via Hathitrust.
- ^ a b Zachary, G. Pascal (1994). Show-stopper!: the breakneck race to create Windows NT and the next generation at Microsoft. New York: The Free Press. p. 158. ISBN 0029356717 – via archive.org.
- ^ «The Next Generation 1996 Lexicon A to Z: Slipstream Release». Next Generation. No. 15. March 1996. p. 41.
- ^ Carr, Nicholas (2018). «‘It’s Not a Bug, It’s a Feature.’ Trite—or Just Right?». wired.com.
- ^ Di Franco, Anthony; Guo, Hui; Cindy, Rubio-González. «A Comprehensive Study of Real-World Numerical Bug Characteristics» (PDF). Archived (PDF) from the original on October 9, 2022.
- ^ Kimbler, K. (1998). Feature Interactions in Telecommunications and Software Systems V. IOS Press. p. 8. ISBN 978-90-5199-431-5.
- ^ Syed, Mahbubur Rahman (July 1, 2001). Multimedia Networking: Technology, Management and Applications: Technology, Management and Applications. Idea Group Inc (IGI). p. 398. ISBN 978-1-59140-005-9.
- ^ Wu, Chwan-Hwa (John); Irwin, J. David (April 19, 2016). Introduction to Computer Networks and Cybersecurity. CRC Press. p. 500. ISBN 978-1-4665-7214-0.
- ^ RFC 1263: «TCP Extensions Considered Harmful» quote: «the time to distribute the new version of the protocol to all hosts can be quite long (forever in fact). … If there is the slightest incompatibly between old and new versions, chaos can result.»
- ^ Lientz, B. P.; Swanson, E. B.; Tompkins, G. E. (1978). «Characteristics of Application Software Maintenance». Communications of the ACM. 21 (6): 466–471. doi:10.1145/359511.359522. S2CID 14950091.
- ^ Amit, Idan; Feitelson, Dror G. (2020). «The Corrective Commit Probability Code Quality Metric». arXiv:2007.10912 [cs.SE].
- ^ An overview of the Software Engineering Laboratory (PDF) (Report). Maryland, USA: Goddard Space Flight Center, NASA. December 1, 1994. pp41–42 Figure 18; pp43–44 Figure 21. CR-189410; SEL-94-005. Archived (PDF) from the original on November 22, 2022. Retrieved November 22, 2022. (bibliography: An overview of the Software Engineering Laboratory)
- ^ a b Cobb, Richard H.; Mills, Harlan D. (1990). «Engineering software under statistical quality control». IEEE Software. 7 (6): 46. doi:10.1109/52.60601. ISSN 1937-4194. S2CID 538311 – via University of Tennessee – Harlan D. Mills Collection.
- ^ McConnell, Steven C. (1993). Code Complete. Redmond, Washington, USA: Microsoft Press. p. 611. ISBN 9781556154843 – via archive.org.
(Cobb and Mills 1990)
- ^ Holzmann, Gerard (March 6, 2009). «Appendix D – Software Complexity» (PDF). In Dvorak, Daniel L. (ed.). NASA Study on Flight Software Complexity (Report). NASA. pdf frame 109/264. Appendix D p.2. Archived (PDF) from the original on March 8, 2022. Retrieved November 22, 2022. (under NASA Office of the Chief Engineer Technical Excellence Initiative)
- ^ Ullman, Ellen (2004). The Bug. Picador. ISBN 978-1-250-00249-5.
External links[edit]
- «Common Weakness Enumeration» – an expert webpage focus on bugs, at NIST.gov
- BUG type of Jim Gray – another Bug type
- Picture of the «first computer bug» at the Wayback Machine (archived January 12, 2015)
- «The First Computer Bug!» – an email from 1981 about Adm. Hopper’s bug
- «Toward Understanding Compiler Bugs in GCC and LLVM». A 2016 study of bugs in compilers
A software bug is an error, flaw or fault in the design, development, or operation of computer software that causes it to produce an incorrect or unexpected result, or to behave in unintended ways. The process of finding and correcting bugs is termed «debugging» and often uses formal techniques or tools to pinpoint bugs. Since the 1950s, some computer systems have been designed to deter, detect or auto-correct various computer bugs during operations.
Bugs in software can arise from mistakes and errors made in interpreting and extracting users’ requirements, planning a program’s design, writing its source code, and from interaction with humans, hardware and programs, such as operating systems or libraries. A program with many, or serious, bugs is often described as buggy. Bugs can trigger errors that may have ripple effects. The effects of bugs may be subtle, such as unintended text formatting, through to more obvious effects such as causing a program to crash, freezing the computer, or causing damage to hardware. Other bugs qualify as security bugs and might, for example, enable a malicious user to bypass access controls in order to obtain unauthorized privileges.[1]
Some software bugs have been linked to disasters. Bugs in code that controlled the Therac-25 radiation therapy machine were directly responsible for patient deaths in the 1980s. In 1996, the European Space Agency’s US$1 billion prototype Ariane 5 rocket was destroyed less than a minute after launch due to a bug in the on-board guidance computer program.[2] In 1994, an RAF Chinook helicopter crashed, killing 29; this was initially blamed on pilot error, but was later thought to have been caused by a software bug in the engine-control computer.[3] Buggy software caused the early 21st century British Post Office scandal, the most widespread miscarriage of justice in British legal history.[4]
In 2002, a study commissioned by the US Department of Commerce’s National Institute of Standards and Technology concluded that «software bugs, or errors, are so prevalent and so detrimental that they cost the US economy an estimated $59 billion annually, or about 0.6 percent of the gross domestic product».[5]
History[edit]
The Middle English word bugge is the basis for the terms «bugbear» and «bugaboo» as terms used for a monster.[6]
The term «bug» to describe defects has been a part of engineering jargon since the 1870s[7] and predates electronics and computers; it may have originally been used in hardware engineering to describe mechanical malfunctions. For instance, Thomas Edison wrote in a letter to an associate in 1878:[8]
… difficulties arise—this thing gives out and [it is] then that «Bugs»—as such little faults and difficulties are called—show themselves[9]
Baffle Ball, the first mechanical pinball game, was advertised as being «free of bugs» in 1931.[10] Problems with military gear during World War II were referred to as bugs (or glitches).[11] In a book published in 1942, Louise Dickinson Rich, speaking of a powered ice cutting machine, said, «Ice sawing was suspended until the creator could be brought in to take the bugs out of his darling.»[12]
Isaac Asimov used the term «bug» to relate to issues with a robot in his short story «Catch That Rabbit», published in 1944.
A page from the Harvard Mark II electromechanical computer’s log, featuring a dead moth that was removed from the device.
The term «bug» was used in an account by computer pioneer Grace Hopper, who publicized the cause of a malfunction in an early electromechanical computer.[13] A typical version of the story is:
In 1946, when Hopper was released from active duty, she joined the Harvard Faculty at the Computation Laboratory where she continued her work on the Mark II and Mark III. Operators traced an error in the Mark II to a moth trapped in a relay, coining the term bug. This bug was carefully removed and taped to the log book. Stemming from the first bug, today we call errors or glitches in a program a bug.[14]
Hopper was not present when the bug was found, but it became one of her favorite stories.[15] The date in the log book was September 9, 1947.[16][17][18] The operators who found it, including William «Bill» Burke, later of the Naval Weapons Laboratory, Dahlgren, Virginia,[19] were familiar with the engineering term and amusedly kept the insect with the notation «First actual case of bug being found.» This log book, complete with attached moth, is part of the collection of the Smithsonian National Museum of American History.[17]
The related term «debug» also appears to predate its usage in computing: the Oxford English Dictionary‘s etymology of the word contains an attestation from 1945, in the context of aircraft engines.[20]
The concept that software might contain errors dates back to Ada Lovelace’s 1843 notes on the analytical engine, in which she speaks of the possibility of program «cards» for Charles Babbage’s analytical engine being erroneous:
… an analysing process must equally have been performed in order to furnish the Analytical Engine with the necessary operative data; and that herein may also lie a possible source of error. Granted that the actual mechanism is unerring in its processes, the cards may give it wrong orders.
«Bugs in the System» report[edit]
The Open Technology Institute, run by the group, New America,[21] released a report «Bugs in the System» in August 2016 stating that U.S. policymakers should make reforms to help researchers identify and address software bugs. The report «highlights the need for reform in the field of software vulnerability discovery and disclosure.»[22] One of the report’s authors said that Congress has not done enough to address cyber software vulnerability, even though Congress has passed a number of bills to combat the larger issue of cyber security.[22]
Government researchers, companies, and cyber security experts are the people who typically discover software flaws. The report calls for reforming computer crime and copyright laws.[22]
The Computer Fraud and Abuse Act, the Digital Millennium Copyright Act and the Electronic Communications Privacy Act criminalize and create civil penalties for actions that security researchers routinely engage in while conducting legitimate security research, the report said.[22]
Terminology[edit]
While the use of the term «bug» to describe software errors is common, many have suggested that it should be abandoned. One argument is that the word «bug» is divorced from a sense that a human being caused the problem, and instead implies that the defect arose on its own, leading to a push to abandon the term «bug» in favor of terms such as «defect», with limited success.[23] Since the 1970s Gary Kildall somewhat humorously suggested to use the term «blunder».[24][25]
In software engineering, mistake metamorphism (from Greek meta = «change», morph = «form») refers to the evolution of a defect in the final stage of software deployment. Transformation of a «mistake» committed by an analyst in the early stages of the software development lifecycle, which leads to a «defect» in the final stage of the cycle has been called ‘mistake metamorphism’.[26]
Different stages of a «mistake» in the entire cycle may be described as «mistakes», «anomalies», «faults», «failures», «errors», «exceptions», «crashes», «glitches», «bugs», «defects», «incidents», or «side effects».[26]
Prevention[edit]
The software industry has put much effort into reducing bug counts.[27][28] These include:
Typographical errors[edit]
Bugs usually appear when the programmer makes a logic error. Various innovations in programming style and defensive programming are designed to make these bugs less likely, or easier to spot. Some typos, especially of symbols or logical/mathematical operators, allow the program to operate incorrectly, while others such as a missing symbol or misspelled name may prevent the program from operating. Compiled languages can reveal some typos when the source code is compiled.
Development methodologies[edit]
Several schemes assist managing programmer activity so that fewer bugs are produced. Software engineering (which addresses software design issues as well) applies many techniques to prevent defects. For example, formal program specifications state the exact behavior of programs so that design bugs may be eliminated. Unfortunately, formal specifications are impractical for anything but the shortest programs, because of problems of combinatorial explosion and indeterminacy.
Unit testing involves writing a test for every function (unit) that a program is to perform.
In test-driven development unit tests are written before the code and the code is not considered complete until all tests complete successfully.
Agile software development involves frequent software releases with relatively small changes. Defects are revealed by user feedback.
Open source development allows anyone to examine source code. A school of thought popularized by Eric S. Raymond as Linus’s law says that popular open-source software has more chance of having few or no bugs than other software, because «given enough eyeballs, all bugs are shallow».[29] This assertion has been disputed, however: computer security specialist Elias Levy wrote that «it is easy to hide vulnerabilities in complex, little understood and undocumented source code,» because, «even if people are reviewing the code, that doesn’t mean they’re qualified to do so.»[30] An example of an open-source software bug was the 2008 OpenSSL vulnerability in Debian.
Programming language support[edit]
Programming languages include features to help prevent bugs, such as static type systems, restricted namespaces and modular programming. For example, when a programmer writes (pseudocode) LET REAL_VALUE PI = "THREE AND A BIT", although this may be syntactically correct, the code fails a type check. Compiled languages catch this without having to run the program. Interpreted languages catch such errors at runtime. Some languages deliberately exclude features that easily lead to bugs, at the expense of slower performance: the general principle being that, it is almost always better to write simpler, slower code than inscrutable code that runs slightly faster, especially considering that maintenance cost is substantial. For example, the Java programming language does not support pointer arithmetic; implementations of some languages such as Pascal and scripting languages often have runtime bounds checking of arrays, at least in a debugging build.
Code analysis[edit]
Tools for code analysis help developers by inspecting the program text beyond the compiler’s capabilities to spot potential problems. Although in general the problem of finding all programming errors given a specification is not solvable (see halting problem), these tools exploit the fact that human programmers tend to make certain kinds of simple mistakes often when writing software.
Instrumentation[edit]
Tools to monitor the performance of the software as it is running, either specifically to find problems such as bottlenecks or to give assurance as to correct working, may be embedded in the code explicitly (perhaps as simple as a statement saying PRINT "I AM HERE"), or provided as tools. It is often a surprise to find where most of the time is taken by a piece of code, and this removal of assumptions might cause the code to be rewritten.
Testing[edit]
Software testers are people whose primary task is to find bugs, or write code to support testing. On some projects, more resources may be spent on testing than in developing the program.
Measurements during testing can provide an estimate of the number of likely bugs remaining; this becomes more reliable the longer a product is tested and developed.[citation needed]
Debugging[edit]
The typical bug history (GNU Classpath project data). A new bug submitted by the user is unconfirmed. Once it has been reproduced by a developer, it is a confirmed bug. The confirmed bugs are later fixed. Bugs belonging to other categories (unreproducible, will not be fixed, etc.) are usually in the minority
Finding and fixing bugs, or debugging, is a major part of computer programming. Maurice Wilkes, an early computing pioneer, described his realization in the late 1940s that much of the rest of his life would be spent finding mistakes in his own programs.[31]
Usually, the most difficult part of debugging is finding the bug. Once it is found, correcting it is usually relatively easy. Programs known as debuggers help programmers locate bugs by executing code line by line, watching variable values, and other features to observe program behavior. Without a debugger, code may be added so that messages or values may be written to a console or to a window or log file to trace program execution or show values.
However, even with the aid of a debugger, locating bugs is something of an art. It is not uncommon for a bug in one section of a program to cause failures in a completely different section,[citation needed] thus making it especially difficult to track (for example, an error in a graphics rendering routine causing a file I/O routine to fail), in an apparently unrelated part of the system.
Sometimes, a bug is not an isolated flaw, but represents an error of thinking or planning on the part of the programmer. Such logic errors require a section of the program to be overhauled or rewritten. As a part of code review, stepping through the code and imagining or transcribing the execution process may often find errors without ever reproducing the bug as such.
More typically, the first step in locating a bug is to reproduce it reliably. Once the bug is reproducible, the programmer may use a debugger or other tool while reproducing the error to find the point at which the program went astray.
Some bugs are revealed by inputs that may be difficult for the programmer to re-create. One cause of the Therac-25 radiation machine deaths was a bug (specifically, a race condition) that occurred only when the machine operator very rapidly entered a treatment plan; it took days of practice to become able to do this, so the bug did not manifest in testing or when the manufacturer attempted to duplicate it. Other bugs may stop occurring whenever the setup is augmented to help find the bug, such as running the program with a debugger; these are called heisenbugs (humorously named after the Heisenberg uncertainty principle).
Since the 1990s, particularly following the Ariane 5 Flight 501 disaster, interest in automated aids to debugging rose, such as static code analysis by abstract interpretation.[32]
Some classes of bugs have nothing to do with the code. Faulty documentation or hardware may lead to problems in system use, even though the code matches the documentation. In some cases, changes to the code eliminate the problem even though the code then no longer matches the documentation. Embedded systems frequently work around hardware bugs, since to make a new version of a ROM is much cheaper than remanufacturing the hardware, especially if they are commodity items.
Benchmark of bugs[edit]
To facilitate reproducible research on testing and debugging, researchers use curated benchmarks of bugs:
- the Siemens benchmark
- ManyBugs[33] is a benchmark of 185 C bugs in nine open-source programs.
- Defects4J[34] is a benchmark of 341 Java bugs from 5 open-source projects. It contains the corresponding patches, which cover a variety of patch type.
Bug management[edit]
Bug management includes the process of documenting, categorizing, assigning, reproducing, correcting and releasing the corrected code. Proposed changes to software – bugs as well as enhancement requests and even entire releases – are commonly tracked and managed using bug tracking systems or issue tracking systems.[35] The items added may be called defects, tickets, issues, or, following the agile development paradigm, stories and epics. Categories may be objective, subjective or a combination, such as version number, area of the software, severity and priority, as well as what type of issue it is, such as a feature request or a bug.
A bug triage reviews bugs and decides whether and when to fix them. The decision is based on the bug’s priority, and factors such as project schedules. The triage is not meant to investigate the cause of bugs, but rather the cost of fixing them. The triage happens regularly, and goes through bugs opened or reopened since the previous meeting. The attendees of the triage process typically are the project manager, development manager, test manager, build manager, and technical experts.[36][37]
Severity[edit]
Severity is the intensity of the impact the bug has on system operation.[38] This impact may be data loss, financial, loss of goodwill and wasted effort. Severity levels are not standardized. Impacts differ across industry. A crash in a video game has a totally different impact than a crash in a web browser, or real time monitoring system. For example, bug severity levels might be «crash or hang», «no workaround» (meaning there is no way the customer can accomplish a given task), «has workaround» (meaning the user can still accomplish the task), «visual defect» (for example, a missing image or displaced button or form element), or «documentation error». Some software publishers use more qualified severities such as «critical», «high», «low», «blocker» or «trivial».[39] The severity of a bug may be a separate category to its priority for fixing, and the two may be quantified and managed separately.
Priority[edit]
Priority controls where a bug falls on the list of planned changes. The priority is decided by each software producer. Priorities may be numerical, such as 1 through 5, or named, such as «critical», «high», «low», or «deferred». These rating scales may be similar or even identical to severity ratings, but are evaluated as a combination of the bug’s severity with its estimated effort to fix; a bug with low severity but easy to fix may get a higher priority than a bug with moderate severity that requires excessive effort to fix. Priority ratings may be aligned with product releases, such as «critical» priority indicating all the bugs that must be fixed before the next software release.
A bug severe enough to delay or halt the release of the product is called a «show stopper»[40] or «showstopper bug».[41] It is named so because it «stops the show» – causes unacceptable product failure.[41]
Software releases[edit]
It is common practice to release software with known, low-priority bugs. Bugs of sufficiently high priority may warrant a special release of part of the code containing only modules with those fixes. These are known as patches. Most releases include a mixture of behavior changes and multiple bug fixes. Releases that emphasize bug fixes are known as maintenance releases, to differentiate it from major releases that emphasize feature additions or changes.
Reasons that a software publisher opts not to patch or even fix a particular bug include:
- A deadline must be met and resources are insufficient to fix all bugs by the deadline.[42]
- The bug is already fixed in an upcoming release, and it is not of high priority.
- The changes required to fix the bug are too costly or affect too many other components, requiring a major testing activity.
- It may be suspected, or known, that some users are relying on the existing buggy behavior; a proposed fix may introduce a breaking change.
- The problem is in an area that will be obsolete with an upcoming release; fixing it is unnecessary.
- «It’s not a bug, it’s a feature».[43] A misunderstanding has arisen between expected and perceived behavior or undocumented feature.
Types[edit]
In software development projects, a mistake or error may be introduced at any stage. Bugs arise from oversight or misunderstanding by a software team during specification, design, coding, configuration, data entry or documentation. For example, a relatively simple program to alphabetize a list of words, the design might fail to consider what should happen when a word contains a hyphen. Or when converting an abstract design into code, the coder might inadvertently create an off-by-one error which can be a «<» where «<=» was intended, and fail to sort the last word in a list.
Another category of bug is called a race condition that may occur when programs have multiple components executing at the same time. If the components interact in a different order than the developer intended, they could interfere with each other and stop the program from completing its tasks. These bugs may be difficult to detect or anticipate, since they may not occur during every execution of a program.
Conceptual errors are a developer’s misunderstanding of what the software must do. The resulting software may perform according to the developer’s understanding, but not what is really needed. Other types:
Arithmetic[edit]
In operations on numerical values, problems can arise that result in unexpected output, slowing of a process, or crashing.[44] These can be from a lack of awareness of the qualities of the data storage such as a loss of precision due to rounding, numerically unstable algorithms, arithmetic overflow and underflow, or from lack of awareness of how calculations are handled by different software coding languages such as division by zero which in some languages may throw an exception, and in others may return a special value such as NaN or infinity.
Control flow[edit]
Control flow bugs are those found in processes with valid logic, but that lead to unintended results, such as infinite loops and infinite recursion, incorrect comparisons for conditional statements such as using the incorrect comparison operator, and off-by-one errors (counting one too many or one too few iterations when looping).
Interfacing[edit]
- Incorrect API usage.
- Incorrect protocol implementation.
- Incorrect hardware handling.
- Incorrect assumptions of a particular platform.
- Incompatible systems. A new API or communications protocol may seem to work when two systems use different versions, but errors may occur when a function or feature implemented in one version is changed or missing in another. In production systems which must run continually, shutting down the entire system for a major update may not be possible, such as in the telecommunication industry[45] or the internet.[46][47][48] In this case, smaller segments of a large system are upgraded individually, to minimize disruption to a large network. However, some sections could be overlooked and not upgraded, and cause compatibility errors which may be difficult to find and repair.
- Incorrect code annotations.
Concurrency[edit]
- Deadlock, where task A cannot continue until task B finishes, but at the same time, task B cannot continue until task A finishes.
- Race condition, where the computer does not perform tasks in the order the programmer intended.
- Concurrency errors in critical sections, mutual exclusions and other features of concurrent processing. Time-of-check-to-time-of-use (TOCTOU) is a form of unprotected critical section.
Resourcing[edit]
- Null pointer dereference.
- Using an uninitialized variable.
- Using an otherwise valid instruction on the wrong data type (see packed decimal/binary-coded decimal).
- Access violations.
- Resource leaks, where a finite system resource (such as memory or file handles) become exhausted by repeated allocation without release.
- Buffer overflow, in which a program tries to store data past the end of allocated storage. This may or may not lead to an access violation or storage violation. These are frequently security bugs.
- Excessive recursion which—though logically valid—causes stack overflow.
- Use-after-free error, where a pointer is used after the system has freed the memory it references.
- Double free error.
Syntax[edit]
- Use of the wrong token, such as performing assignment instead of equality test. For example, in some languages x=5 will set the value of x to 5 while x==5 will check whether x is currently 5 or some other number. Interpreted languages allow such code to fail. Compiled languages can catch such errors before testing begins.
Teamwork[edit]
- Unpropagated updates; e.g. programmer changes «myAdd» but forgets to change «mySubtract», which uses the same algorithm. These errors are mitigated by the Don’t Repeat Yourself philosophy.
- Comments out of date or incorrect: many programmers assume the comments accurately describe the code.
- Differences between documentation and product.
Implications[edit]
The amount and type of damage a software bug may cause naturally affects decision-making, processes and policy regarding software quality. In applications such as human spaceflight, aviation, nuclear power, health care, public transport or automotive safety, since software flaws have the potential to cause human injury or even death, such software will have far more scrutiny and quality control than, for example, an online shopping website. In applications such as banking, where software flaws have the potential to cause serious financial damage to a bank or its customers, quality control is also more important than, say, a photo editing application.
Other than the damage caused by bugs, some of their cost is due to the effort invested in fixing them. In 1978, Lientz et al. showed that the median of projects invest 17 percent of the development effort in bug fixing.[49] In 2020, research on GitHub repositories showed the median is 20%.[50]
Residual bugs in delivered product[edit]
In 1994, NASA’s Goddard Space Flight Center managed to reduce their average number of errors from 4.5 per 1000 lines of code (SLOC) down to 1 per 1000 SLOC.[51]
Another study in 1990 reported that exceptionally good software development processes can achieve deployment failure rates as low as 0.1 per 1000 SLOC.[52] This figure is iterated in literature such as Code Complete by Steve McConnell,[53] and the NASA study on Flight Software Complexity.[54] Some projects even attained zero defects: the firmware in the IBM Wheelwriter typewriter which consists of 63,000 SLOC, and the Space Shuttle software with 500,000 SLOC.[52]
Well-known bugs[edit]
A number of software bugs have become well-known, usually due to their severity: examples include various space and military aircraft crashes. Possibly the most famous bug is the Year 2000 problem or Y2K bug, which caused many programs written long before the transition from 19xx to 20xx dates to malfunction, for example treating a date such as «25 Dec 04» as being in 1904, displaying «19100» instead of «2000», and so on. A huge effort at the end of the 20th century resolved the most severe problems, and there were no major consequences.
The 2012 stock trading disruption involved one such incompatibility between the old API and a new API.
In popular culture[edit]
- In both the 1968 novel 2001: A Space Odyssey and the corresponding 1968 film 2001: A Space Odyssey, a spaceship’s onboard computer, HAL 9000, attempts to kill all its crew members. In the follow-up 1982 novel, 2010: Odyssey Two, and the accompanying 1984 film, 2010, it is revealed that this action was caused by the computer having been programmed with two conflicting objectives: to fully disclose all its information, and to keep the true purpose of the flight secret from the crew; this conflict caused HAL to become paranoid and eventually homicidal.
- In the English version of the Nena 1983 song 99 Luftballons (99 Red Balloons) as a result of «bugs in the software», a release of a group of 99 red balloons are mistaken for an enemy nuclear missile launch, requiring an equivalent launch response, resulting in catastrophe.
- In the 1999 American comedy Office Space, three employees attempt (unsuccessfully) to exploit their company’s preoccupation with the Y2K computer bug using a computer virus that sends rounded-off fractions of a penny to their bank account—a long-known technique described as salami slicing.
- The 2004 novel The Bug, by Ellen Ullman, is about a programmer’s attempt to find an elusive bug in a database application.[55]
- The 2008 Canadian film Control Alt Delete is about a computer programmer at the end of 1999 struggling to fix bugs at his company related to the year 2000 problem.
See also[edit]
- Anti-pattern
- Bug bounty program
- Glitch removal
- Hardware bug
- ISO/IEC 9126, which classifies a bug as either a defect or a nonconformity
- Orthogonal Defect Classification
- Racetrack problem
- RISKS Digest
- Software defect indicator
- Software regression
- Software rot
- Automatic bug fixing
References[edit]
- ^ Mittal, Varun; Aditya, Shivam (January 1, 2015). «Recent Developments in the Field of Bug Fixing». Procedia Computer Science. International Conference on Computer, Communication and Convergence (ICCC 2015). 48: 288–297. doi:10.1016/j.procs.2015.04.184. ISSN 1877-0509.
- ^ «Ariane 501 — Presentation of Inquiry Board report». www.esa.int. Retrieved January 29, 2022.
- ^ Prof. Simon Rogerson. «The Chinook Helicopter Disaster». Ccsr.cse.dmu.ac.uk. Archived from the original on July 17, 2012. Retrieved September 24, 2012.
- ^ «Post Office scandal ruined lives, inquiry hears». BBC News. February 14, 2022.
- ^ «Software bugs cost US economy dear». June 10, 2009. Archived from the original on June 10, 2009. Retrieved September 24, 2012.
{{cite web}}: CS1 maint: unfit URL (link) - ^ Computerworld staff (September 3, 2011). «Moth in the machine: Debugging the origins of ‘bug’«. Computerworld. Archived from the original on August 25, 2015.
- ^ «bug». Oxford English Dictionary (Online ed.). Oxford University Press. (Subscription or participating institution membership required.) 5a
- ^ «Did You Know? Edison Coined the Term «Bug»«. August 1, 2013. Retrieved July 19, 2019.
- ^ Edison to Puskas, 13 November 1878, Edison papers, Edison National Laboratory, U.S. National Park Service, West Orange, N.J., cited in Hughes, Thomas Parke (1989). American Genesis: A Century of Invention and Technological Enthusiasm, 1870-1970. Penguin Books. p. 75. ISBN 978-0-14-009741-2.
- ^ «Baffle Ball». Internet Pinball Database.
(See image of advertisement in reference entry)
- ^ «Modern Aircraft Carriers are Result of 20 Years of Smart Experimentation». Life. June 29, 1942. p. 25. Archived from the original on June 4, 2013. Retrieved November 17, 2011.
- ^ Dickinson Rich, Louise (1942), We Took to the Woods, JB Lippincott Co, p. 93, LCCN 42024308, OCLC 405243, archived from the original on March 16, 2017.
- ^ FCAT NRT Test, Harcourt, March 18, 2008
- ^ «Danis, Sharron Ann: «Rear Admiral Grace Murray Hopper»«. ei.cs.vt.edu. February 16, 1997. Retrieved January 31, 2010.
- ^ James S. Huggins. «First Computer Bug». Jamesshuggins.com. Archived from the original on August 16, 2000. Retrieved September 24, 2012.
- ^ «Bug Archived March 23, 2017, at the Wayback Machine», The Jargon File, ver. 4.4.7. Retrieved June 3, 2010.
- ^ a b «Log Book With Computer Bug Archived March 23, 2017, at the Wayback Machine», National Museum of American History, Smithsonian Institution.
- ^ «The First «Computer Bug», Naval Historical Center. But note the Harvard Mark II computer was not complete until the summer of 1947.
- ^ IEEE Annals of the History of Computing, Vol 22 Issue 1, 2000
- ^ Journal of the Royal Aeronautical Society. 49, 183/2, 1945 «It ranged … through the stage of type test and flight test and ‘debugging’ …»
- ^ Wilson, Andi; Schulman, Ross; Bankston, Kevin; Herr, Trey. «Bugs in the System» (PDF). Open Policy Institute. Archived (PDF) from the original on September 21, 2016. Retrieved August 22, 2016.
- ^ a b c d Rozens, Tracy (August 12, 2016). «Cyber reforms needed to strengthen software bug discovery and disclosure: New America report – Homeland Preparedness News». Retrieved August 23, 2016.
- ^ «News at SEI 1999 Archive». cmu.edu. Archived from the original on May 26, 2013.
- ^ Shustek, Len (August 2, 2016). «In His Own Words: Gary Kildall». Remarkable People. Computer History Museum. Archived from the original on December 17, 2016.
- ^ Kildall, Gary Arlen (August 2, 2016) [1993]. Kildall, Scott; Kildall, Kristin (eds.). «Computer Connections: People, Places, and Events in the Evolution of the Personal Computer Industry» (Manuscript, part 1). Kildall Family: 14–15. Archived from the original on November 17, 2016. Retrieved November 17, 2016.
- ^ a b «Testing experience : te : the magazine for professional testers». Testing Experience. Germany: testingexperience: 42. March 2012. ISSN 1866-5705. (subscription required)
- ^ Huizinga, Dorota; Kolawa, Adam (2007). Automated Defect Prevention: Best Practices in Software Management. Wiley-IEEE Computer Society Press. p. 426. ISBN 978-0-470-04212-0. Archived from the original on April 25, 2012.
- ^ McDonald, Marc; Musson, Robert; Smith, Ross (2007). The Practical Guide to Defect Prevention. Microsoft Press. p. 480. ISBN 978-0-7356-2253-1.
- ^ «Release Early, Release Often» Archived May 14, 2011, at the Wayback Machine, Eric S. Raymond, The Cathedral and the Bazaar
- ^ «Wide Open Source» Archived September 29, 2007, at the Wayback Machine, Elias Levy, SecurityFocus, April 17, 2000
- ^ Maurice Wilkes Quotes
- ^ «PolySpace Technologies history». christele.faure.pagesperso-orange.fr. Retrieved August 1, 2019.
- ^ Le Goues, Claire; Holtschulte, Neal; Smith, Edward K.; Brun, Yuriy; Devanbu, Premkumar; Forrest, Stephanie; Weimer, Westley (2015). «The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs». IEEE Transactions on Software Engineering. 41 (12): 1236–1256. doi:10.1109/TSE.2015.2454513. ISSN 0098-5589.
- ^ Just, René; Jalali, Darioush; Ernst, Michael D. (2014). «Defects4J: a database of existing faults to enable controlled testing studies for Java programs». Proceedings of the 2014 International Symposium on Software Testing and Analysis — ISSTA 2014. pp. 437–440. CiteSeerX 10.1.1.646.3086. doi:10.1145/2610384.2628055. ISBN 9781450326452. S2CID 12796895.
- ^ Allen, Mitch (May–June 2002). «Bug Tracking Basics: A beginner’s guide to reporting and tracking defects». Software Testing & Quality Engineering Magazine. Vol. 4, no. 3. pp. 20–24. Retrieved December 19, 2017.
- ^ Rex Black (2002). Managing The Testing Process (2Nd Ed.). Wiley India Pvt. Limited. p. 139. ISBN 9788126503131. Retrieved June 19, 2021.
- ^ Chris Vander Mey (August 24, 2012). Shipping Greatness — Practical Lessons on Building and Launching Outstanding Software, Learned on the Job at Google and Amazon. O’Reilly Media. pp. 79–81. ISBN 9781449336608.
- ^ Soleimani Neysiani, Behzad; Babamir, Seyed Morteza; Aritsugi, Masayoshi (October 1, 2020). «Efficient feature extraction model for validation performance improvement of duplicate bug report detection in software bug triage systems». Information and Software Technology. 126: 106344. doi:10.1016/j.infsof.2020.106344. S2CID 219733047.
- ^ «5.3. Anatomy of a Bug». bugzilla.org. Archived from the original on May 23, 2013.
- ^ Jones, Wilbur D. Jr., ed. (1989). «Show stopper». Glossary: defense acquisition acronyms and terms (4 ed.). Fort Belvoir, Virginia, USA: Department of Defense, Defense Systems Management College. p. 123. hdl:2027/mdp.39015061290758 – via Hathitrust.
- ^ a b Zachary, G. Pascal (1994). Show-stopper!: the breakneck race to create Windows NT and the next generation at Microsoft. New York: The Free Press. p. 158. ISBN 0029356717 – via archive.org.
- ^ «The Next Generation 1996 Lexicon A to Z: Slipstream Release». Next Generation. No. 15. March 1996. p. 41.
- ^ Carr, Nicholas (2018). «‘It’s Not a Bug, It’s a Feature.’ Trite—or Just Right?». wired.com.
- ^ Di Franco, Anthony; Guo, Hui; Cindy, Rubio-González. «A Comprehensive Study of Real-World Numerical Bug Characteristics» (PDF). Archived (PDF) from the original on October 9, 2022.
- ^ Kimbler, K. (1998). Feature Interactions in Telecommunications and Software Systems V. IOS Press. p. 8. ISBN 978-90-5199-431-5.
- ^ Syed, Mahbubur Rahman (July 1, 2001). Multimedia Networking: Technology, Management and Applications: Technology, Management and Applications. Idea Group Inc (IGI). p. 398. ISBN 978-1-59140-005-9.
- ^ Wu, Chwan-Hwa (John); Irwin, J. David (April 19, 2016). Introduction to Computer Networks and Cybersecurity. CRC Press. p. 500. ISBN 978-1-4665-7214-0.
- ^ RFC 1263: «TCP Extensions Considered Harmful» quote: «the time to distribute the new version of the protocol to all hosts can be quite long (forever in fact). … If there is the slightest incompatibly between old and new versions, chaos can result.»
- ^ Lientz, B. P.; Swanson, E. B.; Tompkins, G. E. (1978). «Characteristics of Application Software Maintenance». Communications of the ACM. 21 (6): 466–471. doi:10.1145/359511.359522. S2CID 14950091.
- ^ Amit, Idan; Feitelson, Dror G. (2020). «The Corrective Commit Probability Code Quality Metric». arXiv:2007.10912 [cs.SE].
- ^ An overview of the Software Engineering Laboratory (PDF) (Report). Maryland, USA: Goddard Space Flight Center, NASA. December 1, 1994. pp41–42 Figure 18; pp43–44 Figure 21. CR-189410; SEL-94-005. Archived (PDF) from the original on November 22, 2022. Retrieved November 22, 2022. (bibliography: An overview of the Software Engineering Laboratory)
- ^ a b Cobb, Richard H.; Mills, Harlan D. (1990). «Engineering software under statistical quality control». IEEE Software. 7 (6): 46. doi:10.1109/52.60601. ISSN 1937-4194. S2CID 538311 – via University of Tennessee – Harlan D. Mills Collection.
- ^ McConnell, Steven C. (1993). Code Complete. Redmond, Washington, USA: Microsoft Press. p. 611. ISBN 9781556154843 – via archive.org.
(Cobb and Mills 1990)
- ^ Holzmann, Gerard (March 6, 2009). «Appendix D – Software Complexity» (PDF). In Dvorak, Daniel L. (ed.). NASA Study on Flight Software Complexity (Report). NASA. pdf frame 109/264. Appendix D p.2. Archived (PDF) from the original on March 8, 2022. Retrieved November 22, 2022. (under NASA Office of the Chief Engineer Technical Excellence Initiative)
- ^ Ullman, Ellen (2004). The Bug. Picador. ISBN 978-1-250-00249-5.
External links[edit]
- «Common Weakness Enumeration» – an expert webpage focus on bugs, at NIST.gov
- BUG type of Jim Gray – another Bug type
- Picture of the «first computer bug» at the Wayback Machine (archived January 12, 2015)
- «The First Computer Bug!» – an email from 1981 about Adm. Hopper’s bug
- «Toward Understanding Compiler Bugs in GCC and LLVM». A 2016 study of bugs in compilers
Ошибки в программировании – дело обычное, хоть и неприятное. В данной статье будет рассказано о том, какими бывают ошибки (баги), а также что собой представляют исключения.
Определение
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Баги обнаруживаются чаще всего в момент отладки или бета-тестирования. Реже – после итогового релиза готовой программы. Вот несколько вариантов багов:
- Появляется сообщение об ошибке, но приложение продолжает функционировать.
- ПО вылетает или зависает. Никаких предупреждений или предпосылок этому не было. Процедура осуществляется неожиданно для пользователя. Возможен вариант, при котором контент перезапускается самостоятельно и непредсказуемо.
- Одно из событий, описанных ранее, сопровождается отправкой отчетов разработчикам.
Ошибки в программах могут привести соответствующее приложение в негодность, а также к непредсказуемым алгоритмам функционирования. Желательно обнаруживать баги на этапе ранней разработки или тестирования. Лишь в этом случае программист сможет оперативно и относительно недорого внести необходимые изменения в код для отладки ПО.
История происхождения термина
Баг – слово, которое используется разработчиками в качестве сленга. Оно произошло от слова «bug» – «жук». Точно неизвестно, откуда в программировании и IT возник соответствующий термин. Существуют две теории:
- 9 сентября 1945 года ученые из Гарварда тестировали очередную вычислительную машину. Она называлась Mark II Aiken Relay Calculator. Устройство начало работать с ошибками. Когда его разобрали, то ученые заметили мотылька, застрявшего между реле. Тогда некая Грейс Хоппер назвала произошедший сбой упомянутым термином.
- Слово «баг» появилось задолго до появления Mark II. Термин использовался Томасом Эдисоном и указывал на мелкие недочеты и трудности. Во время Второй Мировой войны «bugs» называли проблемы с радарной электроникой.
Второй вариант кажется более реалистичным. Это факт, который подтвержден документально. Со временем научились различать различные типы багов в IT. Далее они будут рассмотрены более подробно.
Как классифицируют
Ошибки работы программ разделяются по разным факторам. Классификация у рядовых пользователей и разработчиков различается. То, что для первых – «просто программа вылетела» или «глючит», для вторых – огромная головная боль. Но существует и общепринятая классификация ошибок. Пример – по критичности:
- Серьезные неполадки. Это нарушения работоспособности приложения, которые могут приводить к непредвиденным крупным изменениям.
- Незначительные ошибки в программах. Чаще всего не оказывают серьезного воздействия на функциональность ПО.
- Showstopper. Критические проблемы в приложении или аппаратном обеспечении. Приводят к выходу программы из строя почти всегда. Для примера можно взять любое клиент-серверное приложение, в котором не получается авторизоваться через логин и пароль.
Последний вариант требует особого внимания со стороны программистов. Их стараются обнаружить и устранить в первую очередь. Критические ошибки могут отложить релиз исходной программы на неопределенный срок.
Также существуют различные виды сбоев в плане частоты проявления: постоянные и «разовые». Вторые встречаются редко, чаще – при определенных настройках и действиях со стороны пользователя. Первые появляются независимо от используемой платформы и выполненных клиентом манипуляций.
Иногда может получиться так, что ошибка возникает только на устройстве конкретного пользователя. В данном случае устранение неполадки требует индивидуального подхода. Иногда – полной замены компьютера. Связано это с тем, что никто не будет редактировать исходный код, когда он «глючит» только у одного пользователя.
Виды
Существуют различные типы ошибок в программах в зависимости от типовых условий использования приложений. Пример – сбои, которые возникают при возрастании нагрузки на оперативную память или центральный процессор устройства. Есть баги граничных условий, сбоя идентификаторов, несовместимости с архитектурой процессора (наиболее распространенная проблема на мобильных устройствах).
Разработчики выделяют следующие типы ошибок по уровню сложности:
- «Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
- «Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
- «Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
- «Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Также есть классификация «по критичности». Тут всего два варианта – warning («варнинги») и критические весомые сбои. Первые сопровождаются характерными сообщениями и отчетами для разработчиков. Они не представляют серьезной опасности для работоспособности приложения. При компилировании такие сбои легко исправляются. В отдельных случаях компилятор справляется с этой задачей самостоятельно. А вот критические весомые сбои говорят сами за себя. Они приводят к серьезным нарушениям ПО. Исправляются обычно путем проработки логики и значительных изменений программного кода.
Типы багов
Ошибки в программах бывают:
- логическими;
- синтаксическими;
- взаимодействия;
- компиляционные;
- ресурсные;
- арифметические;
- среды выполнения.
Это – основная классификация сбоев в приложениях и операционных системах. Логические, синтаксические и «среды выполнения» встречаются в разработке чаще остальных. На них будет сделан основной акцент.
Ошибки синтаксиса
Синтаксические баги распространены среди новичков. Они относятся к категории «самых безобидных». С данной категорией ошибок способны справиться компиляторы тех или иных языков. Соответствующие инструменты показывают, где допущена неточность. Остается лишь понять, как исправить ее.
Синтаксические ошибки – ошибки синтаксиса, правил языка. Вот пример в Паскале:

Код написан неверно. Согласно действующим синтаксическим нормам, в Pascal в первой строчке нужно в конце поставить точку с запятой.
Логические
Тут стоит выделить обычные и арифметические типы. Вторые возникают, когда программе при работе необходимо вычислить много переменных, но на каком-то этапе расчетов возникают неполадки или нечто непредвиденное. Пример – получение в результатах «бесконечности».
Логические сбои обычного типа – самые сложные и неприятные. Их тяжелее всего обнаружить и исправить. С точки зрения языка программа может быть написана идеально, но работать неправильно. Подобное явление – следствие логической ошибки. Компиляторы их не обнаруживают.

Выше – пример логической ошибки в программе. Тут:
- Происходит сравнение значения i с 15.
- На экран выводится сообщение, если I = 15.
- В заданном цикле i не будет равно 15. Связано это с диапазоном значений – от 1 до 10.
Может показаться, что ошибка безобидная. В приведенном примере так и есть, но в более крупных программах такое явление приводит к серьезным последствиям.
Время выполнения
Run-time сбои – это ошибка времени выполнения программы. Встречается даже когда исходный код лишен логических и синтаксических ошибок. Связаны такие неполадки с ходом выполнения программного продукта. Пример – в процессе функционирования ПО был удален файл, считываемый программой. Если игнорировать подобные неполадки, можно столкнуться с аварийным завершением работы контента.
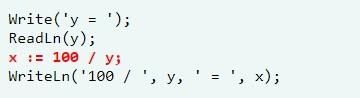
Самый распространенный пример в данной категории – это неожиданное деление на ноль. Предложенный фрагмент кода с точки зрения синтаксиса и логики написан грамотно. Но, если клиент наберет 0, произойдет сбой системы.
Компиляционный тип
Встречается при разработке на языках высокого уровня. Во время преобразований в машинный тип «что-то идет не так». Причиной служат синтаксические ошибки или сбои непосредственно в компиляторе.
Наличие подобных неполадок делает бета-тестирование невозможным. Компиляционные ошибки устраняются при разработке-отладке.
Ресурсные
Ресурсный тип ошибок – это сбои вроде «переполнение буфера» или «нехватка памяти». Тесно связаны с «железом» устройства. Могут быть вызваны действиями пользователя. Пример – запуск «свежих» игр на стареньких компьютерах.
Исправить ситуацию помогают основательные работы над исходным кодом. А именно – полное переписывание программы или «проблемного» фрагмента.
Взаимодействие
Подразумевается взаимодействие с аппаратным или программным окружением. Пример – ошибка при использовании веб-протоколов. Это приведет к тому, что облачный сервис не будет нормально функционировать. При постоянном возникновении соответствующей неполадки остается один путь – полностью переписывать «проблемный» участок кода, ответственный за соответствующий баг.
Исключения и как избежать багов
Исключение – событие, при возникновении которых начинается «неправильное» поведение программы. Механизм, необходимый для стабилизации обработки неполадок независимо от типа ПО, платформ и иных условий. Помогают разрабатывать единые концепции ответа на баги со стороны операционной системы или контента.
Исключения бывают:
- Программными. Они генерируются приложением или ОС.
- Аппаратными. Создаются процессором. Пример – обращение к невыделенной памяти.
Исключения нужны для охвата критических багов. Избежать неполадок помогут отладчики на этапе разработки. А еще – своевременное поэтапное тестирование программы.
P. S. Большой выбор курсов по тестированию есть и в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.
Исключения (исключительные ситуации, exceptions) являются механизмом обработки ошибок, который пришел на смену возврату кода ошибки функциями. Тем не менее, многие разработчики до сих пор используют возврат кода ошибки вместо исключений — в частности очень многие участники конференции C++ Russia 2015 говорили об этом, включая разработчиков Яндекса.
В заметке мы рассмотрим:
- обработку каких ошибок можно выполнять с использованием исключений;
- синтаксические конструкции, введенные в языки для обработки исключений (примерно одинаковые в разных языках программирования — Java, C++, C# и др.).;
- рекомендации по использованию исключений (в т.ч. по книгам о чистоте кода);
Несмотря на то, что примеры программ приводятся на С++, тут не приводятся особенности отдельных языков программирования, связанные с обработкой исключений, а описываются лишь принципы, общие для большинства языков.
Что следует понимать под ошибкой?
Исключения являются механизмом обработки ошибок, при этом под ошибкой имеется ввиду любая ситуация, в которой функция не может продолжить корректное выполнение из-за каких-либо внешних факторов:
- функция отправки данных по сети (через сокет) не может знать как в вашем конкретном приложении должен обрабатываться разрыв соединения;
- функция, выполняющая запрос к базе данных может вырабатывать исключение в случаях если база стала недоступна или в запросе допущена ошибка;
- было бы хорошо, если бы функция вычисления квадратного корня не завершала аварийно работу программы в случае если на вход подано отрицательное число, а вырабатывала бы исключение.
Способы обработки ошибок
Таким образом, под ошибкой надо понимать только те проблемы, которые функция не может решить локально. В этих случаях функция должна как-то известить того, кто ее вызвал о сложившейся проблеме, есть различные способы сделать это:
- возврат кода ошибки. Например, если при отправке сообщения по сети выяснится, что соединение разорвано, функция отправки может вернуть единицу, а при успешной отправке — ноль;
- вернуть заведомо некорректный результат. Например, функция
malloc, выделяющая память в языке Си при ошибке (невозможности выделить память) возвращает ноль, а в остальных случаях — начальный адрес выделенного фрагмента; - вернуть любое допустимое значение и выставить глобальный флаг ошибки (в языке С++ для этого может использоваться глобальная переменная
errno. - аварийно завершить работу (в С++ для этого используются функции
abortилиexit); - выработать исключение (подробнее написано ниже);
Конечно, помимо завершения работы, вы всегда можете записать описание сложившейся ситуации в log-файл (поток cerr в С++) или вывести на экран.
Аварийное завершение работы — это худший способ обработки ошибки, т.к. программист фактически расписывается в своей неспособности что-то исправить.
С точки зрения последовательности выполнения команд, возврат кода ошибки ничем не отличается от возврата некорректного значения или выставления флага ошибки в глобальный объект. Во всех этих случаях функция, которая не знает как корректно обработать входные данные передает эти обязанности непосредственно коду, который ее вызвал. Чаще всего это работает хорошо, однако:
- если вызывающий код не обрабатывает код ошибки (он ведь не обязан это делать), то он продолжает вычисления, но уже с некорректными данными. Такая ситуация выявится не сразу, ведь вы можете получить некорректный результат или аварийный останов совсем с другом месте. Например, в библиотеке Qt есть функция преобразования строки в целое число:
int QString::toInt(bool * ok = 0, int base = 10) const
В случае ошибки она вернет ноль и присвоит значениеfalseаргументуok(который вообще не является обязательным). Если наш код вызывает эту функцию для строки, не являющейся целым число — то он продолжит выполнение, получив в качестве результата ноль (вполне корректное, но неверное значение); - далеко не всегда удается правильно обработать ошибку непосредственно в коде, вызвавшем функцию. В результате получается примерно следующая ситуация:
bool foo(QString str) { bool ok; string.toInt(&ok); if (false == ok) { return false; } // ... some actions } bool bar() { QString str; // ... some actions if (false == foo(str)) return fasle; } }Что в этом плохого? — значительная часть кода делает лишь то, что доставляет код ошибки до точки, в которой его можно корректно обработать. Притом, ни одна из всех этих функций не обязана это делать, т.е. вы в любой момент можете потерять ошибку и приступить к долгой отладке.
В этом контексте, исключения можно рассматривать как механизм доставки информации об ошибки до точки программы, где эту ошибку наиболее естественно обрабатывать. Доставка ошибки при этом будет выполняться точно также, как и серия операторов return в приведенном выше фрагменте кода — каждая функция получившая исключение передает управление «наверх» (раскручивая стек), процесс продолжается до тех пор, пока исключение не попадет в блок trt{}, содержащий обработчик, совместимый с типом исключения.
Исключением также называют объект, некоторого класса, являющийся представлением ошибки (исключительного случая).
Синтаксические конструкции механизма обработки исключений
Фрагмент кода, внутри которого могут вырабатываться исключения должен быть помещен в блок try{}, к которому могут быть добавлены обработчики — блоки catch(ExceptionType) {}. Функция может вырабатывать исключения при помощи оператора throw. Например:
try {
socket = connect_to_server(host); // throw BadHostException or ServerNotAvailableException
send_message(socket, message); // throw ServerNotAvailableException or BadMsgException
}
catch(BadHostException exception) {
// BadHostException hadler
// can charge other host from user
}
catch(ServerNotAvailableException exception) {
// ServerNotAvailableException handler
// can reconnect for example
}
catch(BadMsgException exception) {
// BadMsgException hadler
// can notify user by window
}
catch(...) {
// other types of exceptions hadler
}
При возникновении исключения (вызове throw) в какой либо из функций начинается раскрутка стека (в том числе освобождается память из под всех локальных объектов), до тех пор, пока не будет обнаружен подходящий catch в функции, которая непосредственно или косвенно вызвала функцию, сгенерировавшую исключение.
Исключения могут организовываться в иерархии посредством наследования. Например, в стандартной библиотеке C++ определен базовый класс std::exception, от которого наследуется std::logic_error (класс логических ошибок), являющий базовым для std::out_of_range. Для фрагмента кода, рассмотренного выше, мог быть выделен класс NetworkException, базовый для BadHostException и ServerNotAvailableException. При этом, если при обработке нам не важно какие именно проблемы с сетью произошли — мы можем написать обработчик для базового класса.
К блоку try{} может быть написано несколько обработчиков, совместимых с одним и тем же типом исключения. Блоки catch обрабатываются в порядке их перечисления, поэтому будет выбран тот, который описан выше. Например:
catch(BadHostException exception) {
// BadHostException hadler
}
catch(NetworkException exception) {
// all network exceptions, but not BadHostException
}
catch(ServerNotAvailableException exception) {
// never call, because ServerNotAvailableException was hanled as NetworkException
}
Рекомендации по использованию исключений
Выше описаны общие (подходящие для большинства языков) принципы обработки исключений. Однако, в каждом языке есть свои тонкости. Так, например, в языке Java есть ключевое слово finally, задающее фрагмент кода, который будет выполнен при возникновении исключения любого вида. В языке C++, например: надо учитывать то, что при обработке throw создается копия исключения; в обработчике исключения запись throw; позволяет передать текущее исключение дальше без копирования; и множество других тонкостей [3]. Во многих языках можно задать спецификацию исключений для функции (используйте спецификации исключений), т.е. список исключений, которые могут выходить из нее — если вдруг какой-либо участок кода начнет вырабатывать новый тип исключения — вы получите ошибку на этапе компиляции. Изучите особенности реализации механизма исключений для своего языка программирования.
Исключения являются более безопасным и удобным механизмом, чем коды ошибок — за счет спецификации исключений компилятор гарантирует, что вы не пропустите по невнимательности обработку ошибки, кроме того, ошибки будут сами доставляться до подходящего обработчика. Страуструп пишет, что в ряде случаев только за счет использования исключений удается сократить объем кода обработки ошибок в два раза [1]. В связи с этим, следует использовать исключения вместо кодов ошибок, такой подход окажет положительное влияние на архитектуру всего приложения.
Роберт Мартин рекомендует начинать написание функции с try-catch-finally. Это заставит программиста еще раз задумать о том, какие ошибки могут произойти — на самом деле, почти любая функция может столкнуться с ситуациями, в которых не сможет продолжить вычисления [2].
Старайтесь использовать иерархии исключений. Нередко, внутри библиотеки может вырабатываться огромное количество разных видов исключений, однако пользователю могут быть не важны детали проблемы — например, ему достаточно знать, что видеокарта не поддерживает нужный ему набор функций, но совершенно ненужно знать почему. Мартин советует определять классы исключений в контексте потребностей вызывающей стороны [2], однако чаще всего этого можно достичь при помощи иерархий, т.к. клиент всегда сможет обработать как конкретные, так и базовые классы исключений.
Пишите код, безопасный с точки зрения исключений (exception-safe)
Что такое «код, безопасный с точки зрения исключений»? Пусть имеется какой-то произвольный фрагмент кода. Где-то в процессе выполнения этого кода генерируется исключение и перехватывается снаружи. Этот фрагмент кода безопасен с точки зрения исключений если он, в идеале, отвечает следующим требованиям:
- Все ресурсы, выделенные внутри блока try до генерации исключения, должны быть корректно освобождены;
- Все объекты, созданные внутри блока try до генерации исключения, должны быть корректно уничтожены;
- Должен произойти полный откат всех изменений в системе, внесенных кодом, который выполнился от начала блока try до момента генерации исключения.
Эти три пункта указываются почти в любой литературе, в которой идет речь о безопасности с точки зрения исключений. По большому счету, первые два пункта это частные случаи более общего правила, указанного в третьем пункте. Код, безопасный с точи зрения исключений, это код, обладающий транзакционным поведением.
Транзакционность и «бизнес-логика»
Блоками try следует охватывать те участки кода, которые должны иметь транзакционное поведение с точки зрения «бизнес-логики» самой программы.
Рассмотрим в качестве примера графический редактор, имеющий multi-dialog интерфейс, и следующий сценарий работы: пользователь выбирает у главном меню «Open file(s)», выделяет десять картинок и нажимает «Open». Восемь картинок загружаются корректно, загрузка девятой генерирует исключение.
Для того, чтобы понять, какой именно участок кода следует охватить блоком try, необходимо решить, какая именно логика работы с точки зрения сценария должна быть реализована. В рассматриваемом примере возможны два очевидных варианта, и оба вполне имеют право на существование. Первый — открыть только те картинки, которые корректно загрузились и показать сообщение об ошибке. Второй — показать сообщение об ошибке и выбросить все успешно загруженные картинки, тем самым выполнив полный откат системы. В первом случае элементом транзакции является код загрузки отдельно взятой картинки — он и берется в блок try. Во втором случае элементом транзакции является код загрузки множества картинок, то есть фрагмент, находящийся на один логический этаж выше.
Итак, блоками try следует охватывать участки кода, которые должны представлять собой транзакцию с точки зрения «бизнес-логики». При этом следует стараться расположить блок try как можно выше относительно вложенности функциональности, делая шаги вверх по этажам до тех пор, пока языковая транзакция не начнет противоречить логике, которая должна быть реализована в программе. И логика эта, как показывает практика, может быть очень разнообразной.
Обеспечение транзакционности
Некоторые авторитетные люди, чьи книги издаются чуть ли не миллионными тиражами, утверждают, что одна из причин, по которой исключения лучше чем коды ошибок, заключается в том, что код, занимающийся ремонтом программы можно отделить от логики работы программы, поместив его в блоки catch. К сожалению, этот подход устарел уже на следующий день после выхода первого Стандарта языка C++, а его использование говорит о полном непонимании всей прелести языка.
В идеале, весь код по ремонту программы должен быть реализован на уровне описания типов, то есть так или иначе посредством идиомы владения. В блоках catch следует содержать только код, занимающийся оповещением об ошибке. Если это оконное приложение, то достаточно показать MessageBox, если серверная система, то сделать запись в лог или отправить сообщение по почте.
Следует внимательно следить за тем, чтобы способ оповещения об ошибке не генерировал исключений, поскольку исключение при попытке проинформировать об ошибке — ситуация не из приятных. Если требуется оповестить об ошибке способом, который может сгенерировать исключение (например — отправка сообщения по почте), то такую работу лучше осуществлять в очереди отложенных задач в отдельном потоке, добавляя в блоке catch негенерирующим исключения способом новую отложенную задачу.
Типы данных
Практически во всех ситуациях наиболее естественный тип данных для пользовательских исключений с точки зрения C++ это тип, так или иначе производный от std::exception. Моя рекомендация состоит в том, чтобы в качестве типа данных для пользовательских исключений использовать std::runtime_error, или его наследников, если это необходимо.
Некоторые люди (не буду показывать пальцем) используют оператор new для генерации исключений и перехватывают их по указателю. Такая конструкция в свое время была (а может быть и до сих пор есть) в макросах Visual Assist-а. Такой подход в C++ в корне неверен — применять его можно только в языках со сборщиком мусора (gc). Использование такого подхода в C++ говорит о полном непонимании механизма исключений. Генерировать исключения следует по значению, перехватывать — по константной ссылке.
Классификация и оповещение
Любая ошибка имеет причину и влечет следствие. Используйте виртуальную функцию std::exception::what() для того, чтобы получить человеческое описание причины возникновения ошибки.
Различные варианты наследников std::runtime_error помогут классифицировать тип ошибки для правильного способа оповещения, и, если это все же по каким-то причинам необходимо, для выполнения необходимых действий по приведению программы в корректное работоспособное состояние. Например, исключения различных подсистем могут иметь различный тип данных.
namespace network
{
class error : public std::runtime_error
{
virtual char const* what() const;
};
} // namespace network
namespace ui
{
class error : public std::runtime_error
{
virtual char const* what() const;
};
} // namespace ui
int main()
{
application app;
while(app.alive())
{
try
{
app.run();
}
catch(network::error const& e)
{
std::cout << "Network exception: " << e.what() << std::endl;
mailto("admin@microsoft.com", e.what());
}
catch(ui::error const& e)
{
std::cout << "UI exception: " << e.what() << std::endl;
message_box(e.what());
}
catch(std::exception const& e)
{
std::cout << "Exception: " << e.what() << std::endl;
}
}
return 0;
}
Следствие ошибки напрямую зависит от того места, где исключение было перехвачено. Следствие любого перехваченного исключения в коде, безопасном с точки зрения исключений, это откат системы на блок try, в котором это исключение было сгенерированно. То есть, говоря по-простому, следствие это «что не получилось сделать», в то время как причина это «почему это не получилось сделать». Место генерации исключения и его тип — это причина, место его перехвата — это следствие.
Составление сообщения об ошибке — очень ответственная задача, с которой, к сожалению, зачастую не справляются даже самые крупные программные продукты. Хорошее сообщение об ошибке должно содержать информацию как о причине ошибки, так и о ее следствии. Вот пример хорошего сообщения об ошибке:
Не могу загрузить изображение (следствие):
недостаточно прав для чтения файла 001.jpg (причина)
Подведем итоги
В этой статье я уделил много времени описанию того, что стоит понимать под исключительной ситуацией (ошибкой). Это очень важно, т.к. может возникать соблазн использовать этот механизм для других целей. Даже если это сработает эффективно в каком-либо случае, код будет очень трудно читаться.
Можно порассуждать о том, должна ли функция вычисления квадратного корня или оператор деления вырабатывать исключения при отрицательном или нулевом значениях аргумента. Во-первых это могло быть не эффективно, во-вторых, скорее всего гораздо удобнее в таких случаях проверить корректность аргумента до вызова функции, чем обрабатывать ошибки после. Однако, подобная предварительная проверка была бы не эффективной например для функции преобразования строки в число.
Тут же, можно вспомнить, что исключения не используются во многих проектах по причинам недостаточной эффективности — например в Яндекс.Браузере. Кроме того, исключения не использовались в библиотеке Qt (по крайней мере 4.х версии) из-за сложности их реализации на некоторых архитектурах. Тот факт, что в настоящее время библиотека Qt сейчас использует механизм исключений означает, что его поддерживает подавляющее большинство компиляторов С++ под самые разные платформы.
Мое личное мнение — нужно стараться использовать исключения вместо кодов ошибок, однако при этом надо думать и об архитектуре приложения, и об удобстве использования ваших классов и функций. В большинстве случаев исключения помогут вам написать более чистый, понятный и безопасный код. В совсем редких случаях они окажут какое-либо заметное влияние на производительность, ведь исключения вообще не должны вырабатываться в программе часто — это механизм обработки ошибок, которые не должны сыпаться как из рога изобилия.
Пишите код, транзакционный с точки зрения исключений. Реализуйте транзакционность на уровне описания типов данных, максимально минимизируя ремонт программы в блоках catch. Сопоставляйте блокам try соответствующие транзакции с точки зрения «бизнес-логики». Используйте std::runtime_error или его наследников в качестве типов данных для исключений. Генерируйте исключения по значению, перехватывайте по константной ссылке. Классифицируйте ошибки, если это необходимо. Предоставляйте понятное человеку сообщение об ошибке; указывайте как причину, так и следствие. Оповещайте об исключении способом, не генерирующим исключения.
Литература по теме обработки исключений:
- Б. Страуструп Язык программирования С++. Специальное издание. Пер. с англ. – М.: Издательство Бином, 2011 г. – 1136 с.
- Мартин Р. Чистый код. Создание, анализ и рефакторинг. Библиотека программиста. – СПб.: Питер, 2014. – 464 с.
- Мейерс С. Эффективное использование С++. 35 новых рекомендаций по улучшению ваших программ и проектов. – М.: ДМК Пресс, 2014. – 294с.