8.4.1 Принципы обнаружения и исправления ошибок
В реальных условиях
прием двоичных символов всегда происходит
с ошибками, когда вместо символа 1
принимается символ 0 и наоборот. Ошибки
могут возникать из-за помех, действующих
в канале связи (особенно помех импульсного
характера), изменения за время передачи
характеристик канала (например,
замирания), снижения уровня передачи,
нестабильности амплитудно- и фазочастотных
характеристик канала и т. п.
Общепринятым
критерием оценки качества передачи в
дискретных каналах является нормированная
на знак или символ допустимая вероятность
ошибки для данного вида сообщений. Так,
допустимая вероятность ошибки при
телеграфной связи может составлять
![]()
(на знак), а при передаче данных — не
более
![]()
(на символ). Для обеспечения таких
значений вероятностей одного улучшения
только качественных показателей канала
связи может оказаться недостаточным.
Поэтому, основной мерой является
применение специальных методов повышения
качества приема передаваемой информации.
Эти методы можно разбить на две группы.
К первой группе
относятся методы увеличения
помехоустойчивости приема единичных
элементов (символов) дискретной
информации, связанные с выбором уровня
сигнала, отношения сигнал/помеха
(энергетические характеристики), ширины
полосы канала, методов приема и т. д.
Ко второй группе
относятся методы обнаружения и исправления
ошибок, основанные на искусственном
введении избыточности в передаваемое
сообщение. Наиболее эффективно
избыточность используется при применении
помехоустойчивых (корректирующих)
кодов.
При передаче данных
осуществляется объединение отдельных
единичных элементов в кодовые комбинации,
по которым определяется принятое
сообщение. У обычного (не помехоустойчивого)
кода для каждой кодовой комбинации во
всей совокупности есть другая комбинация,
отличающаяся от первой лишь одним
разрядом. При искажении одного из
разрядов кодовая комбинация превратится
в другую и поэтому принятое сообщение
будет выдано с ошибкой.
Помехоустойчивое,
или избыточное
кодирование
применяется для обнаружения и (или)
исправления ошибок, возникающих при
передаче по дискретному каналу.
Отличительное свойство помехоустойчивого
кодирования состоит в том, что избыточность
источника, образованного выходом кодера,
больше, чем избыточность источника на
входе кодера. Помехоустойчивое кодирование
используется в различных системах
связи, при хранении и передаче данных
в сетях ЭВМ, в бытовой и профессиональной
аудио- и видеотехнике, основанной на
цифровой записи.
При использовании
помехоустойчивого кода передаются в
канал не все кодовые комбинации, которые
можно сформировать из имеющегося числа
разрядов, а лишь обладающие определенным
свойством, и называемые разрешенными.
Другие неиспользованные комбинации
называются запрещенными.
Введение дополнительных отличных
признаков в переданные комбинации
позволяет существенно повысить
правильность приема. Помехоустойчивые
коды подразделяются на коды, которые
обнаруживают
ошибки, и
коды, которые исправляют
ошибки.
Для двоичного кода
все множество кодовых комбинаций равно
N=2n
. При
использовании кодов,
обнаруживающих ошибки,
все множество n-разрядных
комбинаций разбивается на два
непересекающихся подмножества. Одно
подмножество называется разрешенной,
а другое запрещенной
(рис 8.7 а). Эти подмножества известны,
как на передающей, так и на приемной
сторонах. Если в результате искажений
передаваемых кодов комбинация перейдет
в подмножество запрещенных комбинаций,
то ошибка будет обнаружена. Такие коды
позволяют только определить наличие
ошибок, но не указывающие номер искаженных
разрядов.

Передаются только
разрешенные кодовые комбинации, которые
имеют определенное свойство. Если
принятая кодовая комбинация относится
к разрешенным, то считается, что ошибки
нет.
При необходимости
исправления некоторых возникающих
искажений
поступают следующим образом. Все
множество кодовых комбинаций N
разбивают на N0<N
непересекающихся подмножеств. Каждое
из этих подмножеств, приписывается к
одной из N0
разрешенных комбинаций (рис 8.7 б). В
каждом подмножестве существует одна
разрешенная комбинация. Если принятая
комбинация Аj
входит в подмножество N0j
(AjNoj),
то принимается решение, что передана
комбинация Aj.
То есть, если принятая кодовая комбинация
осталась в том же подмножестве, что и
передаваемая, то прием будет без ошибки.
Если кодовая комбинация в результате
искажений переходит в другое подмножество,
то прием будет с ошибкой.
Коды, которые не
только обнаруживают ошибку, но и указывают
номер искаженной позиции, называются
кодами с
исправлением ошибок.
Как было сказано
выше, при использовании помехоустойчивого
кода в канале связи передаются только
разрешенные кодовые комбинации. Если
бы не было помех, то для передачи этих
кодовых комбинаций потребовалось бы
меньшее число разрядов m:
![]()
(8.17)
Таким образом,
обнаружение и исправление возникающих
в каналах связи ошибок достигается за
счет введения в передаваемые кодовые
комбинации избыточных разрядов.
Рассмотрим
возможность обнаружения и исправления
ошибок на простейшем примере. Предположим,
что информация передается одноразрядным
двоичным кодом. То есть передается
информация 0 или 1. Число возможных
кодовых комбинаций
![]() ,
,
где
![]() ,
,![]() .
.
В каждой кодовой
комбинации добавим еще один разряд:
![]() .
.
Число кодовых
комбинаций
![]() .
.
Эти комбинации
составляют множество, состоящее из:
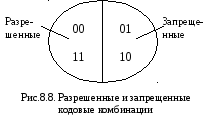
00, 01, 10, 11.
Это множество
разделим на два подмножества разрешенных
и запрещенных комбинаций. К числу
разрешенных отнесем те комбинации, у
которых сумма единиц или нулей всегда
четная – это комбинации:
00 и 11.
При таком выделении
разрешенных комбинаций любая одиночная
(или нечетная) ошибка будет изменять
число единиц на нечетное. Принятая
кодовая комбинация в этом случае
переходит в подмножество запрещенных
и ошибка будет обнаружена (рис. 8.8).
Е сли
сли
в кодовую комбинацию ввести количество
дополнительных разрядов, то можно не
только обнаруживать, но и исправлять
ошибки. Если разрешенные комбинации
определить таким образом, что любые из
них отличаются друг от друга не менее
чем тремя разрядами, то одиночная ошибка
может быть исправлена. Возможность
исправления одиночной ошибки в этом
случае связана с тем, что ошибочная
комбинация будет отличаться от истинной
только одним разрядом и останется в
области, относящейся к передаваемой
разрешенной комбинации.
Рис. 8.9. Геометрическая
модель помехоустойчивого кода
Рассмотрим сказанное
на геометрической модели трехразрядного
двоичного кода при помощи которого
можно получить 23=8
комбинаций. А именно: 000, 001, 010, 011, 100, 101,
110, 111. Каждую новую комбинацию можно
представить точкой в трехмерном
пространстве (рис. 8.9).
Для исправления
одиночной ошибки разобьем все множества
комбинации 110 и 001. Эти комбинации
отличаются друг от друга тремя разрядами.
Любая одиночная ошибка оставляет кодовую
комбинацию в области, относящейся к
передаваемой комбинации. Так, при
искажении одного разряда в комбинации
001 она превратится в 000, или в 100, или в
101. Все эти комбинации находятся в той
же области, что и комбинация 001.
Рассмотренные
примеры показывают, что для обнаружения
одиночных ошибок кодовые комбинации
должны различаться не менее чем двумя
разрядами. Для исправления одиночной
ошибки кодовые комбинации должны
различаться не менее чем тремя разрядами.
Это различие
именуют кодовым
(Хэмминговым) расстоянием.
Под кодовым
расстоянием
понимают
минимальное
число позиций, на которых символы данной
кодовой комбинации отличаются от
символов другой кодовой комбинации.
Например, для показанных на рисунке
8.10, кодовое расстояние d
равно 3.

Рис. 8.10. Кодовое
расстояние между двумя кодовыми
комбинациями
Поэтому можно
сказать, что возможности по обнаружению
или исправлению ошибок определяются
числом позиций, на которых отличаются
разрешенные кодовые комбинации, то есть
кодовым расстоянием.
Кодовое расстояние
между i-й
и j-й
кодовыми комбинациями
![]() определяется по формуле
определяется по формуле
![]() ,
,
(8.18)
где
![]() — значение символов
— значение символов![]() -й
-й
позиции j-й и i-й
кодовых комбинаций, знакозначает суммирование по модулю 2
(правила сложения по модулю 2: (1+1=0;
1+0=0+1=1; 0+0=0).
Соседние файлы в папке Пособие ТЕЗ_рус12
- #
- #
- #
- #
- #
- #
- #
- #
- #
Назначение помехоустойчивого кодирования – защита информации от помех и ошибок при передаче и хранении информации. Помехоустойчивое кодирование необходимо для устранения ошибок, которые возникают в процессе передачи, хранения информации. При передачи информации по каналу связи возникают помехи, ошибки и небольшая часть информации теряется.

Без использования помехоустойчивого кодирования было бы невозможно передавать большие объемы информации (файлы), т.к. в любой системе передачи и хранении информации неизбежно возникают ошибки.
Рассмотрим пример CD диска. Там информация хранится прямо на поверхности диска, в углублениях, из-за того, что все дорожки на поверхности, часто диск хватаем пальцами, елозим по столу и из-за этого без помехоустойчивого кодирования, информацию извлечь не получится.

Использование кодирования позволяет извлекать информацию без потерь даже с поврежденного CD/DVD диска, когда какая либо область становится недоступной для считывания.
В зависимости от того, используется в системе обнаружение или исправление ошибок с помощью помехоустойчивого кода, различают следующие варианты:
- запрос повторной передачи (Automatic Repeat reQuest, ARQ): с помощью помехоустойчивого кода выполняется только обнаружение ошибок, при их наличии производится запрос на повторную передачу пакета данных;
- прямое исправление ошибок (Forward Error Correction, FEC): производится декодирование помехоустойчивого кода, т. е. исправление ошибок с его помощью.
Возможен также гибридный вариант, чтобы лишний раз не гонять информацию по каналу связи, например получили пакет информации, попробовали его исправить, и если не смогли исправить, тогда отправляется запрос на повторную передачу.
Исправление ошибок в помехоустойчивом кодировании
Любое помехоустойчивое кодирование добавляет избыточность, за счет чего и появляется возможность восстановить информацию при частичной потере данных в канале связи (носителе информации при хранении). В случае эффективного кодирования убирали избыточность, а в помехоустойчивом кодировании добавляется контролируемая избыточность.
Простейший пример – мажоритарный метод, он же многократная передача, в котором один символ передается многократно, а на приемной стороне принимается решение о том символе, количество которых больше.
Допустим есть 4 символа информации, А, B, С,D, и эту информацию повторяем несколько раз. В процессе передачи информации по каналу связи, где-то возникла ошибка. Есть три пакета (A1B1C1D1|A2B2C2D2|A3B3C3D3), которые должны нести одну и ту же информацию.

Но из картинки справа, видно, что второй символ (B1 и C1) они отличаются друг от друга, хотя должны были быть одинаковыми. То что они отличаются, говорит о том, что есть ошибка.
Необходимо найти ошибку с помощью голосования, каких символов больше, символов В или символов С? Явно символов В больше, чем символов С, соответственно принимаем решение, что передавался символ В, а символ С ошибочный.
Для исправления ошибок нужно, как минимум 3 пакета информации, для обнаружения, как минимум 2 пакета информации.
Параметры помехоустойчивого кодирования
Первый параметр, скорость кода R характеризует долю информационных («полезных») данных в сообщении и определяется выражением: R=k/n=k/m+k
- где n – количество символов закодированного сообщения (результата кодирования);
- m – количество проверочных символов, добавляемых при кодировании;
- k – количество информационных символов.
Параметры n и k часто приводят вместе с наименованием кода для его однозначной идентификации. Например, код Хэмминга (7,4) значит, что на вход кодера приходит 4 символа, на выходе 7 символов, Рида-Соломона (15, 11) и т.д.
Второй параметр, кратность обнаруживаемых ошибок – количество ошибочных символов, которые код может обнаружить.
Третий параметр, кратность исправляемых ошибок – количество ошибочных символов, которые код может исправить (обозначается буквой t).
Контроль чётности
Самый простой метод помехоустойчивого кодирования это добавление одного бита четности. Есть некое информационное сообщение, состоящее из 8 бит, добавим девятый бит.
Если нечетное количество единиц, добавляем 0.
1 0 1 0 0 1 0 0 | 0
Если четное количество единиц, добавляем 1.
1 1 0 1 0 1 0 0 | 1
Если принятый бит чётности не совпадает с рассчитанным битом чётности, то считается, что произошла ошибка.
1 1 0 0 0 1 0 0 | 1
Под кратностью понимается, всевозможные ошибки, которые можно обнаружить. В этом случае, кратность исправляемых ошибок 0, так как мы не можем исправить ошибки, а кратность обнаруживаемых 1.
Есть последовательность 0 и 1, и из этой последовательности составим прямоугольную матрицу размера 4 на 4. Затем для каждой строки и столбца посчитаем бит четности.
Прямоугольный код – код с контролем четности, позволяющий исправить одну ошибку:

И если в процессе передачи информации допустим ошибку (ошибка нолик вместо единицы, желтым цветом), начинаем делать проверку. Нашли ошибку во втором столбце, третьей строке по координатам. Чтобы исправить ошибку, просто инвертируем 1 в 0, тем самым ошибка исправляется.
Этот прямоугольный код исправляет все одно-битные ошибки, но не все двух-битные и трех-битные.
Рассчитаем скорость кода для:
- 1 1 0 0 0 1 0 0 | 1
Здесь R=8/9=0,88
- И для прямоугольного кода:
Здесь R=16/24=0,66 (картинка выше, двадцать пятую единичку (бит четности) не учитываем)
Более эффективный с точки зрения скорости является первый вариант, но зато мы не можем с помощью него исправлять ошибки, а с помощью прямоугольного кода можно. Сейчас на практике прямоугольный код не используется, но логика работы многих помехоустойчивых кодов основана именно на прямоугольном коде.
Классификация помехоустойчивых кодов
- Непрерывные — процесс кодирования и декодирования носит непрерывный характер. Сверточный код является частным случаем непрерывного кода. На вход кодера поступил один символ, соответственно, появилось несколько на выходе, т.е. на каждый входной символ формируется несколько выходных, так как добавляется избыточность.
- Блочные (Блоковые) — процесс кодирования и декодирования осуществляется по блокам. С точки зрения понимания работы, блочный код проще, разбиваем код на блоки и каждый блок кодируется в отдельности.
По используемому алфавиту:
- Двоичные. Оперируют битами.
- Не двоичные (код Рида-Соломона). Оперируют более размерными символами. Если изначально информация двоичная, нужно эти биты превратить в символы. Например, есть последовательность 110 110 010 100 и нужно их преобразовать из двоичных символов в не двоичные, берем группы по 3 бита — это будет один символ, 6, 6, 2, 4 — с этими не двоичными символами работают не двоичные помехоустойчивые коды.
Блочные коды делятся на
- Систематические — отдельно не измененные информационные символы, отдельно проверочные символы. Если на входе кодера присутствует блок из k символов, и в процессе кодирования сформировали еще какое-то количество проверочных символов и проверочные символы ставим рядом к информационным в конец или в начало. Выходной блок на выходе кодера будет состоять из информационных символов и проверочных.
- Несистематические — символы исходного сообщения в явном виде не присутствуют. На вход пришел блок k, на выходе получили блок размером n, блок на выходе кодера не будет содержать в себе исходных данных.
В случае систематических кодов, выходной блок в явном виде содержит в себе, то что пришло на вход, а в случае несистематического кода, глядя на выходной блок нельзя понять что было на входе.

Смотря на картинку выше, код 1 1 0 0 0 1 0 0 | 1 является систематическим, на вход поступило 8 бит, а на выходе кодера 9 бит, которые в явном виде содержат в себе 8 бит информационных и один проверочный.

Код Хэмминга
Код Хэмминга — наиболее известный из первых самоконтролирующихся и самокорректирующихся кодов. Позволяет устранить одну ошибку и находить двойную.

Код Хэмминга (7,4) — 4 бита на входе кодера и 7 на выходе, следовательно 3 проверочных бита. С 1 по 4 информационные биты, с 6 по 7 проверочные (см. табл. выше). Пятый проверочный бит y5, это сумма по модулю два 1-3 информационных бит. Сумма по модулю 2 это вычисление бита чётности.
Декодирование кода Хэмминга
Декодирование происходит через вычисление синдрома по выражениям:

Синдром это сложение бит по модулю два. Если синдром не нулевой, то исправление ошибки происходит по таблице декодирования:

Расстояние Хэмминга
Расстояние Хэмминга — число позиций, в которых соответствующие символы двух кодовых слов одинаковой длины различны. Если рассматривать два кодовых слова, (пример на картинке ниже, 1 0 1 1 0 0 1 и 1 0 0 1 1 0 1) видно что они отличаются друг от друга на два символа, соответственно расстояние Хэмминга равно 2.

Кратность исправляемых ошибок и обнаруживаемых, связано минимальным расстоянием Хэмминга. Любой помехоустойчивый код добавляет избыточность с целью увеличить минимальное расстояние Хэмминга. Именно минимальное расстояние Хэмминга определяет помехоустойчивость.
Помехоустойчивые коды
Современные коды более эффективны по сравнению с рассматриваемыми примерами. В таблице ниже приведены Коды Боуза-Чоудхури-Хоквингема (БЧХ)

Из таблицы видим, что там один класс кода БЧХ, но разные параметры n и k.
- n — количество символов на входе.
- k — количество символов на выходе.
- t — кратность исправляемых ошибок.
- Отношение k/n — скорость кода.
- G (энергетический выигрыш) — величина, показывающая на сколько можно уменьшить отношение сигнал/шум (Eb/No) для обеспечения заданной вероятности ошибки.
Несмотря на то, что скорость кода близка, количество исправляемых ошибок может быть разное. Количество исправляемых ошибок зависит от той избыточности, которую добавим и от размера блока. Чем больше блок, тем больше ошибок он исправляет, даже при той же самой избыточности.
Пример: помехоустойчивые коды и двоичная фазовая манипуляция (2-ФМн). На графике зависимость отношения сигнал шум (Eb/No) от вероятности ошибки. За счет применения помехоустойчивых кодов улучшается помехоустойчивость.

Из графика видим, код Хэмминга (7,4) на сколько увеличилась помехоустойчивость? Всего на пол Дб это мало, если применить код БЧХ (127, 64) выиграем порядка 4 дБ, это хороший показатель.
Компромиссы при использовании помехоустойчивых кодов
Чем расплачиваемся за помехоустойчивые коды? Добавили избыточность, соответственно эту избыточность тоже нужно передавать. Нужно: увеличивать пропускную способность канала связи, либо увеличивать длительность передачи.

Компромисс:
- Достоверность vs полоса пропускания.
- Мощность vs полоса пропускания.
- Скорость передачи данных vs полоса пропускания
Необходимость чередования (перемежения)
Все помехоустойчивые коды могут исправлять только ограниченное количество ошибок t. Однако в реальных системах связи часто возникают ситуации сгруппированных ошибок, когда в течение непродолжительного времени количество ошибок превышает t.
Например, в канале связи шумов мало, все передается хорошо, ошибки возникают редко, но вдруг возникла импульсная помеха или замирания, которые повредили на некоторое время процесс передачи, и потерялся большой кусок информации. В среднем на блок приходится одна, две ошибки, а в нашем примере потерялся целый блок, включая информационные и проверочные биты. Сможет ли помехоустойчивый код исправить такую ошибку? Эта проблема решаема за счет перемежения.
Пример блочного перемежения:

На картинке, всего 5 блоков (с 1 по 25). Код работает исправляя ошибки в рамках одного блока (если в одном блоке 1 ошибка, код его исправит, а если две то нет). В канал связи отдается информация не последовательно, а в перемешку. На выходе кодера сформировались 5 блоков и эти 5 блоков будем отдавать не по очереди а в перемешку. Записали всё по строкам, но считывать будем, чтобы отправлять в канал связи, по столбцам. Информация в блоках перемешалась. В канале связи возникла ошибка и мы потеряли большой кусок. В процессе приема, мы опять составляем таблицу, записываем по столбцам, но считываем по строкам. За счет того, что мы перемешали большое количество блоков между собой, групповая ошибка равномерно распределится по блокам.

Екатерина Андреевна Гапонько
Эксперт по предмету «Информатика»
Задать вопрос автору статьи
Определение 1
Код Хэмминга — это самый популярный первый самокорректирующийся код.
Введение
Целью помехоустойчивой системы кодирования является обеспечение защиты информации от вероятных ошибок помех при информационных обменах и сохранении данных. Помехоустойчивая система кодирования позволяет ликвидировать возникающие при информационном обмене ошибки, а также ошибки при хранении информации. При трансляции информационных данных по каналам связи, возможно появление помех и ошибок. При этом какая-то часть информации может быть утеряна. Без применения помехоустойчивого кодирования нет возможности передачи значительных информационных объёмов, поскольку практически во всех системах трансляции информации и её сохранения всегда возможно появление ошибок.
Повышение квалификации для учителей
Получите официальное удостоверение государственного образца и пройдите аттестацию
Узнать подробнее
Существуют следующие возможные варианты, которые отличаются применением обнаружения или ликвидации ошибок при помощи помехоустойчивого кода:
- Запрашивается повторная передача информации. При помощи помехоустойчивого кода осуществляется лишь нахождение ошибок, а затем запрашивается повторная передача информационного пакета.
- Выполняется непосредственная коррекция ошибок. То есть, выполняется декодирование помехоустойчивого кода и при этом ликвидируются ошибки.
- Гибрид первых двух вариантов. То есть при обнаружении ошибки делается попытка исправления ошибки, и если попытка оказалась неудачной, то выполняется запрос повторной передачи данных.
Исправление ошибок при помехоустойчивом кодировании
Все методы помехоустойчивого кодирования предполагают избыточность кода, что и позволяет выполнить восстановление данных при их частичной утере по различным причинам. При эффективном кодировании убирается избыточность кода, а при помехоустойчивом кодировании формируется избыточность, величина которой контролируется. Простейшим примером может служить мажоритарная методика кодирования, при которой выполняется многократная передача одного символа, а при его получении оставляется тот символ, число опознаний которого максимально.
«Код Хэмминга» 👇
Существует некоторый набор параметров помехоустойчивого кодирования:
-
Кодовая скорость R, характеризующая долю полезных (несущих информацию) данных в сообщениях. Вычисляется по следующей формуле: $R = k / n = k / m+k$, где:
- $n$ является числом символов кодового сообщения.
- $m$ является числом символов, предназначенных для проверки.
- $k$ число символов информации.
Величины $n$ и $k$ иногда приводятся совместно с именем кода, чтобы можно было его однозначно идентифицировать. К примеру, код Хэмминга (7, 4).
-
Величина кратности обнаруженных ошибок. То есть число символов с ошибками, которое код способен определить.
-
Величина кратности исправленных ошибок. То есть число символов с ошибками, которые код способен скорректировать (обозначим символом t).
Контроль чётности
Наиболее простым способом помехоустойчивого кодирования является прибавление одного бита чётности. Предположим, имеется какое-то сообщение, которое состоит из восьми бит. Нужно к нему прибавить ещё один бит, девятый.
При нечётном количестве единиц прибавляем нуль:
1 0 1 0 0 1 0 0 | 0
При чётном количестве единиц прибавляем единицу:
1 1 0 1 0 1 0 0 | 1
Когда при приёме информации полученный бит чётности не соответствует рассчитанному биту чётности, то фиксируется ошибка.
Классификация помехоустойчивых кодов
Существует следующая классификация помехоустойчивых кодов:
- Непрерывный код. Процедура формирования кодов и их декодирования происходит в непрерывном режиме. Свёрточный код считается частным случаем непрерывных кодов. На вход кодирующего устройства приходит код одного символа, на его выходе появляется несколько символьных кодов, то есть каждому входящему символу соответствует формирование нескольких выходных символов, поскольку добавлены избыточные коды.
- Блочный код. Процедура формирования кодов и их декодирования выполняется по блочно. Блочная система кодирования считается более простой, то есть всё пересылаемое сообщение разбивается на ряд блоков и выполняется поочерёдная кодировка каждого.
По применяемому символьному набору помехоустойчивые системы кодирования делятся на:
- Двоичное кодирование. Используется битовая система.
- Не двоичное кодирование. Используется преобразование исходных двоичных кодов в различные символы.
В свою очередь блочные коды подразделяются на:
- Систематический код. Выполняется разделение на собственно не изменяемые символы, несущие нужную информацию, и на символы, по которым выполняется проверка отсутствия ошибок.
- Несистематический код. В этом коде исходное сообщение не присутствует явно. На вход поступает блок, размером в k, на выходе формируется блок, равный n. Выходной блок кодирующего устройства не содержит в явном виде начальной информации.
То есть при систематической системе кодирования на выходе будет присутствовать информация, пришедшая на вход, а при несистематической системе кодирования невозможно увидеть в выходном блоке исходную информацию.
Код Хэмминга
Замечание 1
Код Хэмминга является самым известным из первоначальных систем кодирования, которые обладали свойством самоконтроля и могли корректировать ошибки. Он даёт возможность исправить одиночную ошибку и обнаружить двойную.
Ниже приведена методика кодирования по Хэммингу:

Рисунок 1. Методика кодирования по Хэммингу. Автор24 — интернет-биржа студенческих работ
Код Хэмминга (7,4) подразумевает наличие четырёх бит на входе кодирующего устройства и семь на его выходе, то есть три бита являются проверочными. Биты с первого по четвёртый являются информационными битами, шестой и седьмой — это проверочные биты, а пятый проверочный бит является суммой по модулю два с первого по третий информационные биты. Сумма по модулю два считается вычислением бита чётности.
Декодирование кодировки Хэмминга выполняется посредством определения синдрома по выражениям:

Рисунок 2. Декодирование кодировки Хэмминга. Автор24 — интернет-биржа студенческих работ
Синдромом является сложение битов по модулю два. Если синдром не равняется нулю, то коррекция ошибки выполняется согласно таблице декодирования:

Рисунок 3. Таблица декодирования. Автор24 — интернет-биржа студенческих работ
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Принципы помехоустойчивого кодирования
Помехоустойчивым (корректирующим) кодированием называется кодирование при котором осуществляется обнаружение либо обнаружение и исправление ошибок в принятых кодовых комбинациях.
Возможность помехоустойчивого кодирования осуществляется на основании теоремы, сформулированной Шенноном, согласно ей:
если производительность источника (Hи’(A)) меньше пропускной способности канала связи (Ск), то существует по крайней мере одна процедура кодирования и декодирования при которой вероятность ошибочного декодирования сколь угодно мала, если же производительность источника больше пропускной способности канала, то такой процедуры не существует.
Основным принципом помехоустойчивого кодирования является использование избыточных кодов, причем если для кодирования сообщения используется простой код, то в него специально вводят избыточность. Необходимость избыточности объясняется тем, что в простых кодах все кодовые комбинации являются разрешенными, поэтому при ошибке в любом из разрядов приведет к появлению другой разрешенной комбинации, и обнаружить ошибку будет не возможно. В избыточных кодах для передачи сообщений используется лишь часть кодовых комбинаций (разрешенные комбинации). Прием запрещенной кодовой комбинации означает ошибку. Причем, в процессе приема закодированного сообщения возможны три случая (рисунок 3).

Рисунок 3 — Случаи приема закодированного сообщения
Прием сообщения без ошибок является оптимальным, но возможен только если канал связи идеальный. В этом случае помехоустойчивое декодирование не нужно.
В реальном канале из-за воздействия помех происходят ошибки в принимаемых кодовых комбинациях. Если принимаемая кодовая комбинация в результате воздействия помех перешла (трансформировалась) из одной разрешенной комбинации в другую, то определить ошибку не возможно, даже при использовании помехоустойчивого кодирования.
Если же передаваемая разрешенная кодовая комбинация, в результате воздействия помех, трансформируется в запрещенную комбинация, то в этом случае существует возможность обнаружить ошибку и исправить ее.
Помехоустойчивое кодирование может осуществляться двумя способами: с обнаружением ошибок либо с исправлением ошибок. Возможность кода обнаруживать или исправлять ошибки определяется кодовым расстоянием.
Если осуществляется кодирование с обнаружением ошибок, то кодовое расстояние должно быть хотя бы на единицу больше чем кратность обнаруживаемых ошибок, т. е.
d0? qо ош + 1.
Если данное условие не выполняется, то одни из ошибок обнаруживаются, а другие нет.
Если осуществляется кодирование с исправлением ошибок, то кодовое расстояние должно быть хотя бы на единицу больше удвоенного значения кратности исправляемых ошибок, т. е.
d0? 2qи ош + 1.
Если данное условие не выполняется, то одни из ошибок исправляются, а другие нет.
Следует отметить, что если код способен исправить одну ошибку (qи ош = 1), что соответствует кодовому расстоянию 3 (d0 = 1?2+1 = 3), то обнаружить он может две ошибки, т. к.
qо ош = d0 – 1 = 2.
Декодирование помехоустойчивых кодов
Декодирование — это процесс перехода от вторичного отображения сообщения к первичному алфавиту.
Декодирование помехоустойчивых кодов может осуществляться тремя способами: сравнения, синдромным и мажоритарным.
Способ сравнения основан на том, что, принятая кодовая комбинация сравнивается со всеми разрешенными комбинациями, которые заранее известны на приеме. Если принятая комбинация не совпадает ни с одной из разрешенных, выносится решение о принятии запрещенной комбинации. Недостатком данного способа является громоздкость и необходимость большого времени для декодирования в случае применения многоразрядных кодов. Данный способ используется в кодах с обнаружением ошибок.
Синдромный способ основан на вычислении определенным образом контрольного числа — синдрома ошибки (С). Если синдром ошибки равен нулю, то кодовая комбинация принята верно, если синдром не равен нулю, то комбинация принята не верно. Данный способ может быть использован в кодах с исправлением ошибок, в этом случае синдром указывает не только на наличие ошибки в кодовой комбинации, но и на место положение этой ошибки в кодовой комбинации. Для двоичного кода знание местоположения ошибки достаточно для ее исправления. Это объясняется тем, что любой символ кодовой комбинации может принимать всего два значения и если символ ошибочный, то его необходимо инвертировать. Следовательно, синдрома ошибки достаточно для исправления ошибок, если d0? 2qи ош + 1.
Мажоритарное декодирование основано на том, что каждый информационный символ кодовой комбинации определяется нескольким линейными выражениями через другие символы кодовой комбинации. Если принята комбинация без ошибок, то все соотношения остаются и все выражения дают одинаковые результаты (единицу или ноль). При ошибке в одном из разрядов эти соотношения нарушаются, в результате чего одни линейные выражения равны нулю, а другие единице. Решение о принятом символе определяется по большинству: если в результате вычислений выражений больше нулей, то принимается решение о принятии нуля, если больше единиц, то принимается решение о приеме единицы. Если, при декодировании, результаты вычисления выражений дают одинаковое число единиц и нулей, то при определении принятого символа приоритет имеет принятый символ, значение которого в данный момент определяется.
Классификация корректирующих кодов
Классификация корректирующих кодов представлена схемой (рисунок 4)
Блочные — это коды, в которых передаваемое сообщение разбивается на блоки и каждому блоку соответствует своя кодовая комбинация (например, в телеграфии каждой букве соответствует своя кодовая комбинация).

Рисунок 4 — Классификация корректирующих кодов
Непрерывные — коды, в которых сообщение не разбивается на блоки, а проверочные символы располагаются между информационными.
Неразделимые — это коды, в кодовых комбинациях которых нельзя выделить проверочные разряды.
Разделимые — это коды, в кодовых комбинациях которых можно указать положение проверочных разрядов, т. е. кодовые комбинации можно разделить на информационную и проверочную части.
Систематические (линейные) — это коды, в которых проверочные символы определяются как линейные комбинации информационных символов, в таких кодах суммирование по модулю два двух разрешенных кодовых комбинаций также дает разрешенную комбинацию. В несистематических кодах эти условия не выполняются.
Код с постоянным весом
Данный код относится к классу блочных не разделимых кодов. В нем все разрешенные кодовые комбинации имеют одинаковый вес. Примером кода с постоянным весом является Международный телеграфный код МТК-3. В этом коде все разрешенные кодовые комбинации имеют вес равный трем, разрядность же комбинаций n=7. Таким образом, из 128 комбинаций (N0 = 27 = 128) разрешенными являются Nа = 35 (именно столько комбинаций из всех имеют W=3). При декодировании кодовых комбинаций осуществляется вычисление веса кодовой комбинации и если W?3, то выносится решение об ошибке. Например, из принятых комбинаций 0110010, 1010010, 1000111 ошибочной является третья, т. к. W=4. Данный код способен обнаруживать все ошибки нечетной кратности и часть ошибок четной кратности. Не обнаруживаются только ошибки смещения, при которых вес комбинации не изменяется, например, передавалась комбинация 1001001, а принята 1010001 (вес комбинации не изменился W=3). Код МТК-3 способен только обнаруживать ошибки и не способен их исправлять. При обнаружении ошибки кодовая комбинация не используется для дальнейшей обработки, а на передающую сторону отправляется запрос о повторной передаче данной комбинации. Поэтому данный код используется в системах передачи информации с обратной связью.
Код с четным числом единиц
Данный код относится к классу блочных, разделимых, систематических кодов. В нем все разрешенные кодовые комбинации имеют четное число единиц. Это достигается введением в кодовую комбинацию одного проверочного символа, который равен единице если количество единиц в информационной комбинации нечетное и нулю ? если четное. Например:
При декодировании осуществляется поразрядное суммирование по модулю два всех элементов принятой кодовой комбинации и если результат равен единице, то принята комбинация с ошибкой, если результат равен нулю принята разрешенная комбинация. Например:
101101 = 1 + 0 + 1 + 1 + 0 + 1 = 0 — разрешенная комбинация
101111 = 1 + 0 + 1 + 1 + 1 + 1 = 1 — запрещенная комбинация.
Данный код способен обнаруживать как однократные ошибки, так и любые ошибки нечетной кратности, но не способен их исправлять. Данный код также используется в системах передачи информации с обратной связью.
Код Хэмминга
Код Хэмминга относится к классу блочных, разделимых, систематических кодов. Кодовое расстояние данного кода d0=3 или d0=4.
Блочные систематические коды характеризуются разрядностью кодовой комбинации n и количеством информационных разрядов в этой комбинации k остальные разряды являются проверочными (r):
r = n — k.
Данные коды обозначаются как (n,k).
Рассмотрим код Хэмминга (7,4). В данном коде каждая комбинация имеет 7 разрядов, из которых 4 являются информационными,
При кодировании формируется кодовая комбинация вида:
а1 а2 а3 а4 b1 b2 b
где аi — информационные символы;
bi — проверочные символы.
В данном коде проверочные элементы bi находятся через линейные комбинации информационных символов ai, причем, для каждого проверочного символа определяется свое правило. Для определения правил запишем таблицу синдромов кода (С) (таблица 3), в которой записываются все возможные синдромы, причем, синдромы имеющие в своем составе одну единицу соответствуют ошибкам в проверочных символах:
- синдром 100 соответствует ошибке в проверочном символе b1;
- синдром 010 соответствует ошибке в проверочном символе b2;
- синдром 001 соответствует ошибке в проверочном символе b3.
Синдромы с числом единиц больше 2 соответствуют ошибкам в информационных символах. Синдромы для различных элементов кодовой комбинации аi и bi должны быть различными.
Таблица 3 — Синдромы кода Хэмминга (7;4)
| Число | Элементы синдрома | Элементы кодовой | ||
| синдрома | С1 | С2 | С3 | комбинации |
| 1 | 0 | 0 | 1 | b3 |
| 2 | 0 | 1 | 0 | b2 |
| 3 | 0 | 1 | 1 | a1 |
| 4 | 1 | 0 | 0 | b1 |
| 5 | 1 | 0 | 1 | a2 |
| 6 | 1 | 1 | 0 | a3 |
| 7 | 1 | 1 | 1 | a4 |
Определим правило формирования элемента b3. Как следует из таблицы, ошибке в данном символе соответствует единица в младшем разряде синдрома С4. Поэтому, из таблицы, необходимо отобрать те элементы аi у которых, при возникновении ошибки, появляется единица в младшем разряде. Наличие единиц в младшем разряде, кроме b3,соответствует элементам a1, a2 и a4. Просуммировав эти информационные элементы получим правило формирования проверочного символа:
b3 = a1 + a2 + a4
Аналогично определяем правила для b2 и b1:
b2 = a1 + a3 + a4
b1 = a2 + a3 + a4
Пример 3, необходимо сформировать кодовую комбинацию кода Хэмминга (7,4) соответствующую информационным символам 1101.
В соответствии с проверочной матрицей определяем bi:
b1 = 1 + 0 + 1 = 0; b2 = 1 + 0 + 1=1; b3 = 1 + 1 + 1 = 1.
Добавляем проверочные символы к информационным и получаем кодовую комбинацию:
Biр = 1101001.
![]()
В теории циклических кодов все преобразования кодовых комбинаций производятся в виде математических операций над полиномами (степенными функциями). Поэтому двоичные комбинации преобразуют в полиномы согласно выражения:
Аi(х) = аn-1xn-1 + аn-2xn-2 +…+ а0x0
где an-1, … коэффициенты полинома принимающие значения 0 или 1. Например, комбинации 1001011 соответствует полином
Аi(х) = 1?x6 + 0?x5 + 0?x4 + 1?x3 + 0?x2 + 1?x+1?x0 ? x6 + x3 + x+1.
При формировании кодовых комбинаций над полиномами производят операции сложения, вычитания, умножения и деления. Операции умножения и деления производят по арифметическим правилам, сложение заменяется суммированием по модулю два, а вычитание заменяется суммированием.
Разрешенные кодовые комбинации циклических кодов обладают тем свойством, что все они делятся без остатка на образующий или порождающий полином G(х). Порождающий полином вычисляется с применением ЭВМ. В приложении приведена таблица синдромов.
Этапы формирования разрешенной кодовой комбинации разделимого циклического кода Biр(х).
1. Информационная кодовая комбинация Ai преобразуется из двоичной формы в полиномиальную (Ai(x)).
2. Полином Ai(x) умножается на хr,
Ai(x)?xr
где r количество проверочных разрядов:
r = n — k.
3. Вычисляется остаток от деления R(x) полученного произведения на порождающий полином:
R(x) = Ai(x)?xr/G(x).
4. Остаток от деления (проверочные разряды) прибавляется к информационным разрядам:
Biр(x) = Ai(x)?xr + R(x).
5. Кодовая комбинация Bip(x) преобразуется из полиномиальной формы в двоичную (Bip).
Пример 4. Необходимо сформировать кодовую комбинацию циклического кода (7,4) с порождающим полиномом G(x)=х3+х+1, соответствующую информационной комбинации 0110.
1. Преобразуем комбинацию в полиномиальную форму:
Ai = 0110 ? х2 + х = Ai(x).
2. Находим количество проверочных символов и умножаем полученный полином на xr:
r = n – k = 7 – 4 =3
Ai(x)?xr = (х2 + х)? x3 = х5 + х4
3. Определяем остаток от деления Ai(x)?xr на порождающий полином, деление осуществляется до тех пор пока наивысшая степень делимого не станет меньше наивысшей степени делителя:
R(x) = Ai(x)?xr/G(x)

4. Прибавляем остаток от деления к информационным разрядам и переводим в двоичную систему счисления:
Biр(x) = Ai(x)?xr+ R(x) = х5 + х4 + 1? 0110001.
5. Преобразуем кодовую комбинацию из полиномиальной формы в двоичную:
Biр(x) = х5 + х4 + 1 ? 0110001 = Biр
Как видно из комбинации четыре старших разряда соответствуют информационной комбинации, а три младших — проверочные.
Формирование разрешенной кодовой комбинации неразделимого циклического кода.
Формирование данных комбинаций осуществляется умножением информационной комбинации на порождающий полином:
Biр(x) = Ai(x)?G(x).
Причем умножение можно производить в двоичной форме.
Пример 5, необходимо сформировать кодовую комбинацию неразделимого циклического кода используя данные примера 2, т. е. G(x) = х3+х+1, Ai(x) = 0110, код (7,4).
1. Переводим комбинацию из двоичной формы в полиномиальную:
Ai = 0110? х2+х = Ai(x)
2. Осуществляем деление Ai(x)?G(x)

3. Переводим кодовую комбинацию из полиномиальной форы в двоичную:
Bip(x) = х5+х4+х3+х ? 0111010 = Bip
В этой комбинации невозможно выделить информационную и проверочную части.
Матричное представление систематических кодов
Систематические коды, рассмотренные выше (код Хэмминга и разделимый циклический код) удобно представить в виде матриц. Рассмотрим, как это осуществляется.
Поскольку систематические коды обладают тем свойством, что сумма двух разрешенных комбинаций по модулю два дают также разрешенную комбинацию, то для формирования комбинаций таких кодов используют производящую матрицу Gn,k. С помощью производящей матрицы можно получить любую кодовую комбинацию кода путем суммирования по модулю два строк матрицы в различных комбинациях. Для получения данной матрицы в нее заносятся исходные комбинации, которые полностью определяют систематический код. Исходные комбинации определяются исходя из условий:
1) все исходные комбинации должны быть различны;
2) нулевая комбинация не должна входить в число исходных комбинаций;
3) каждая исходная комбинация должна иметь вес не менее кодового расстояния, т. е. W?d0;
4) между любыми двумя исходными комбинациями расстояние Хэмминга должно быть не меньше кодового расстояния, т. е. dij?d0.
Производящая матрица имеет вид:

Производящая подматрица имеет k строк и n столбцов. Она образована двумя подматрицами: информационной (включает элементы аij) и проверочной (включает элементы bij). Информационная матрица имеет размеры k?k, а проверочная — r?k.
В качестве информационной подматрицы удобно брать единичную матрицу Ekk:

Проверочная подматрица Gr,k строится путем подбора различных r-разрядных комбинаций, удовлетворяющих следующим правилам:
1) в каждой строке подматрицы количество единиц должно быть не менее d0-1;
2) сумма по модулю два двух любых строк должна иметь не менее d0-2 единицы;
Полученная таким образом подматрица Gr,k приписывается справа к подматрице Ekk, в результате чего получается производящая матрица Gn,k. Затем, используя производящую матрицу, можно получить любую комбинацию кода путем суммирования двух и более строк по модулю два в различных комбинациях.
Пример 6. Необходимо построить производящую матрицу кода Хэмминга способного исправлять 1 ошибку и имеющего n=7. Закодировать с помощью полученной матрицы комбинацию Ai=1101.
Определяем кодовое расстояние:
d0=2qи ош+1= 2?1+1=3.
Для кодов с d0=3 количество проверочных разрядов определяется по формуле:
r=log2(n+1)= log28=3.
Определяем разрядность информационной части:
k = n — r = 7 — 4 =3.
Запишем все возможные комбинации проверочной подматрицы: 000, 001, 010, 011, 100, 101, 110, 111. Выберем из этих комбинаций те, что удовлетворяют правилам:
1) в каждой строке не менее d0-1, этому условию соответствуют комбинации 011, 101, 110, 111;
2) сумма двух любых комбинаций по модулю два содержит единиц не менее d0-2:

3) записываем проверочную подматрицу:

4) приписываем полученную подматрицу к единичной и получаем производящую матрицу:

Если произвести определение d0 для исходных комбинаций полученной матрицы (определив расстояние Хэмминга для всех пар комбинаций), то оно окажется равным 3.
Для кодирования заданной комбинации Ai, необходимо просуммировать те строки матрицы G, которые в информационной части имеют единицу на том месте, на котором они находятся в комбинации Аi. Для заданной комбинации 1101 единичными разрядами являются а1, а2, а4. В матрице G единицы на этих местах имеют строки: первая, вторая и четвертая. Просуммировав их получаем разрешенную комбинацию заданного кода.

Сравнивая полученную кодовую комбинацию Bip с комбинацией полученной примере 3, для которой также использована комбинация Ai=1101, видим что они одинаковы.
Для кода Хэмминга выше были определены правила формирования проверочных символов bk:

Эти правила можно отобразить в виде проверочной матрицы Нn,k. Она состоит из n столбцов (соответствует разрядности кодовой комбинации) и r столбцов (соответствует количеству проверочных разрядов кодовой комбинации). В правой части матрицы указываются синдромы, соответствующие ошибкам в проверочных символах, в левой части записываются элементы информационной части комбинации, причем, те элементы, которые участвуют в образовании определенного элемента bi равны единицы, а те которые не участвуют — нулю.

В данном случае обведенные пунктиром проверочные элементы образуют единичную матрицу. Проверочная матрица позволяет определить ошибочный разряд, поскольку каждый столбец данной матрицы представляет собой синдром соответствующего символа. При этом строки матрицы будут соответствовать разрядам синдрома Ck. Например, согласно приведенной проверочной матрице, синдром соответствующий ошибку в разряде а1 имеет вид 011, в разряде а2 — 101, в разряде а3 — 110, в разряде а4 — 111, в разряде b1 — 100, в разряде b2 — 010, в разряде b3 — 001. Также с помощью проверочной матрицы легко определить проверочные и символы и сформировать кодовую комбинацию. Например, необходимо сформировать кодовую комбинацию кода Хэмминга (7,4) соответствующую информационным символам 1101.
В соответствии с проверочной матрицей определяем bi:
b1 = 1 + 0 + 1 = 0; b2 = 1 + 0 + 1=0; b3 = 1 + 1 + 1 = 1.
Добавляем проверочные символы к информационным и получаем кодовую комбинацию:
Biр = 1101001.
Также проверочную матрицу можно построить и другим способом. Для этого сначала строится единичная матрица Еr. К которой слева приписывается подматрица Dk,r. Каждая строка этой подматрицы соответствует столбцу проверочных разрядов подматрицы Сr,k производящей матрицы Gn,k.

Такое преобразование строк матрицы в столбцы называется транспонированием.
В результате получаем

Декодирование циклических кодов
При декодировании таких кодов (разделимых и неразделимых) используется Синдромный способ. Вычисление синдрома осуществляется в три этапа:
1. принятая комбинация Bip’ преобразуется их двоичной формы в полиномиальную (Bip(x));
2. осуществляется деление Bip(x) на порождающий полином G(x) в результате чего определяется синдром ошибки C(x) (остаток от деления);
3. синдром ошибки преобразуется из полиномиальной формы в двоичную;
4. По проверочной матрице или таблице синдромов определяется ошибочный разряд;
5. Ошибочный разряд в Bip’(x) инвертируется;
6. Исправленная комбинация преобразуется из полиномиальной формы в двоичную Bip.
делением принятой кодовой комбинации Biр’(x) на порождающий полином G(x), который заранее известен на приеме. Остаток от деления и является синдромом ошибки С(х).
Мажоритарное декодирование циклических кодов
Мажоритарное декодирование может применятся только для декодирования систематических кодов (кода Хэмминга, циклического разделимого кода). Рассмотрим мажоритарное декодирование на примере циклического кода.